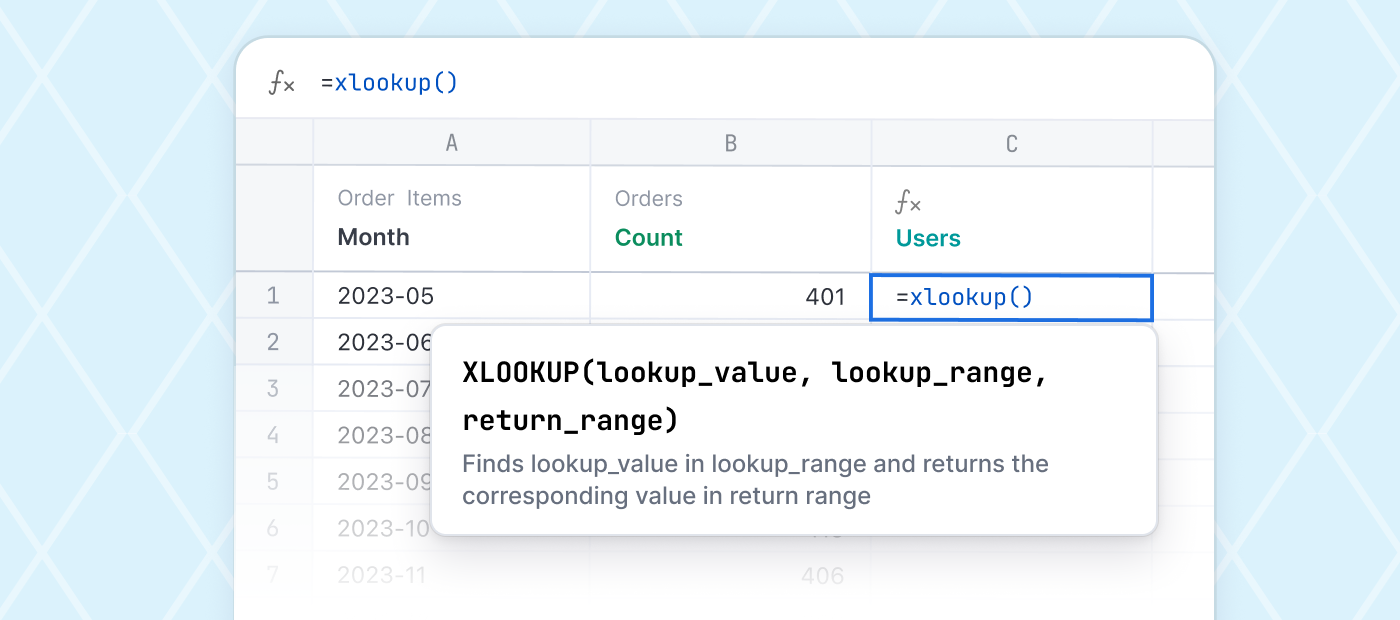
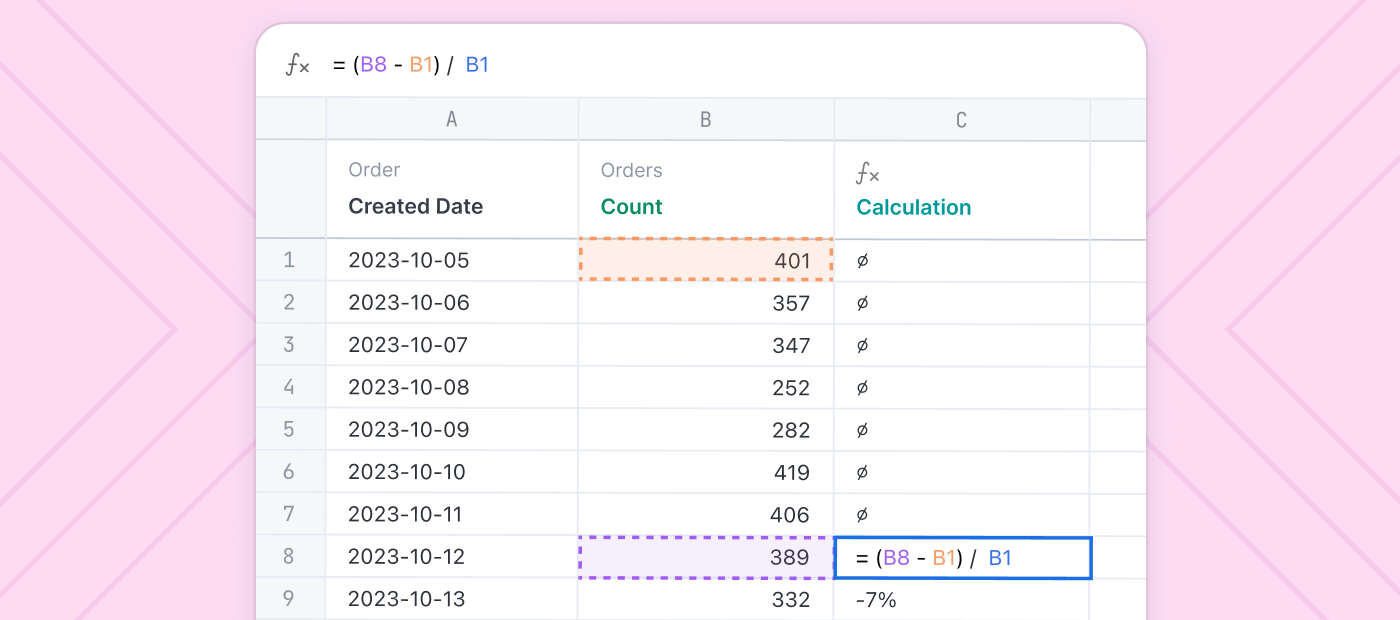
Do you model in dbt or BI?
From a technical perspective, both dbt and any BI tool with a semantic layer are capable of data modeling. The key difference is interactivity: dbt models must be compiled ahead of time, a process that typically takes minutes, while the semantic layer of a BI tool applies modeling logic at query time. dbt is great for core facts — or “nouns” as Tristan calls them. But pieces of logic that need to change dynamically depending on the query, like aggregations (measures) and filters, are best executed just-in-time via the semantic layer.
Many blog posts have been written about how to best use dbt with a BI-based semantic layer, including this great one by my colleague Anika. But often, when people ask “dbt or BI?”, they already know about the technical tradeoffs and are really asking about architecture: should dbt be the only interface between my data and my BI tool? Should I shove a dbt model in front of every table, just to keep the interface entirely in dbt?
As a software engineer, I find something appealing about this idea: well-defined interfaces are good, portability is good, and pulling all logic into dbt accomplishes both.
But…well-defined interfaces are only good if they are stable — i.e. they don’t change much — and this is where the strategy breaks down.
The interface of any real, actively used data set constantly changes: fields are being added or removed and relationships are changing. And if you build and update a dbt model every time your data or analysis changes, rather than just modifying the query in your BI tool, the work adds up.
This gets even worse when the dbt models and BI tool are managed by different teams — the wait balloons from a few minutes to days or even weeks as that team prioritizes and implements the change.
I’ve talked to several teams who have gone down this path. Invariably, they realize a dbt-only modeling strategy creates a bottleneck that prevents them from keeping up with the data needs of their business. In addition to ballooned wait times, this also leads to a bloated model that becomes increasingly difficult to manage.
The equivalent in software engineering would be creating a separate library in your codebase. It’s a great idea if you need to share the code with more than one application, but it comes with a cost: every time the library changes, you need to build, release, and update the dependencies of other projects. This is why software engineers only do this when they have to.
I love dbt — I helped build it. But, these scenarios have become too common, and they slow down the business and bog down data engineering resources with low-value, repetitive tasks.
Getting the most value from data modeling, be it in dbt or a BI-based semantic layer, requires being thoughtful about when to use it.
Here are the scenarios where it does make sense to move models into dbt: #
Scenario 1: dbt for portability #
dbt models are consumable by any tool that integrates with SQL, which is pretty much any data tool. So, if you need data in multiple places, managing the model in dbt is a great choice. But don’t fall into the trap of assuming all your models (or even all fields in your model) need to be portable. Try to keep the surface area small, or you’ll end up in the same bottlenecked situation I described above.
When you discover you need to use a model or field elsewhere, move it down to dbt (here’s an example of pushing newly modeled concepts from Omni → dbt). Otherwise, let the logic live in the more flexible BI layer. And don’t be afraid to let part of a model live in dbt, and then layer on more fields and logic in the BI layer.
Scenario 2: dbt for materialization #
dbt builds its model as views and tables in the data warehouse, which can be a form of optimization: if you need to perform the same heavy transformation every time a query or set of queries run, then you can save time and money by using dbt to pre-compute it and save the results in a table.
This approach comes with the added complexity of updating the table as new data comes in, and dbt has built an orchestration product and features like incremental updating to make this flexible and powerful. Materializing with dbt is also a nice way to encapsulate the optimization logic, control changes to it, and potentially allow a separate team to manage it. But, once again, only apply this optimization when you need it — you’re introducing the complexity of managing and orchestrating the model and data refreshes when you use it.
Scenario 3: dbt for a “data set product” #
There are some situations where a data set should be thought of as a product, and dbt is a home run for these use cases because it allows you to control everything from the data model (interface), update frequency, and materialization logic. Sometimes the data set is a product you’re selling to customers outside of your organization, for example in the Snowflake Data Marketplace. But even if you aren’t selling the data, sometimes it’s useful to think of an internal data set as a product. In my experience, this is true for:
Completeness
If the model comprises several data sets that need to be normalized to a common structure and unioned together, it makes sense to do this upfront in dbt.
For example: Omni runs in many regions and environments around the world and we ETL data from each into Snowflake to do product analysis. We built our original product analysis on just our most active environment and iterated on it until we had a set of useful reports. Then, we built dbt models to union together the tables from each region. Eventually, the number of regions was large enough that maintaining a dbt model for each table became onerous, so we built a dbt macro that automatically unions together all of the tables for all regions and environments.
Consequences
If using imperfect data would lead to dire consequences, implementing a model up front with correctness checks is a good idea, and dbt is a great tool for this.
For example: If you're building a model to train a self-driving car on safety protocols or analyze data to detect early signs of disease, you should probably model first — accuracy and consistency matter here!
But, if you're trying to get real-time insights on new features or marketing tests that are being added and changed frequently, the flexibility to explore first will help you quickly identify early signals of issues or success. Once again, resist the temptation to assume all your data sets are products. It can be easy to say all data must always be perfect, but most decisions wouldn’t change if the numbers are off by 1% or even 5%.
The most important thing to remember is that dbt and BI are better together, and the optimal workflow is to move parts of your data model between them, as needed. So if anyone on your team advocates for all logic to live in one place or another, they’re missing the forest for the trees. Let the dbt layer handle the parts of the data model that must be portable, optimized through materialization, or productized. Then, let the BI data model sit on top to give users the flexibility to use the data in many different ways.
Omni’s integration with dbt embraces this idea that models should be layered, and it should be easy to move between the BI layer and dbt. In Omni, you can promote a model, or part of a model, to dbt in a single click, and Omni automatically detects and uses the new dbt model. And because we know documentation and shared understanding are critical, you can also pull model definitions and documentation from dbt into Omni to help anyone exploring or building models easily access that curated context.
So, do you model in dbt or BI? The best answer is that you should take a hybrid approach that allows you to use dbt for metrics that are stable and your BI semantic layer when you need to maintain flexibility. If you’d like to learn more about how customers use dbt and Omni together, we’d love to show you.