Humans are constantly making trade-offs between pragmatic and scalable – move fast and break things, Macgyver, or the bush fix versus Six Sigma manufacturing, business process management, or software engineering. It’s about finding the right balance between unscalable problem solving and paying the upfront cost to creating robust long-term solutions (Randall Munroe did the math). The reality is great systems combine both – taking shortcuts on the small stuff, focusing time and effort on the core. For individuals it means picking dinner is easy, but picking a partner or a job requires careful consideration. For businesses, it means buying software or services to handle problems that aren’t core like payroll, email, or analytics and focusing time and effort on differentiators. For a data team it means figuring out how to balance self-serve and governed data models for your analysis.
But building and maintaining robust systems comes with cost. There is a reason why Excel still reigns as the most ubiquitous data tool in the world. Data teams are constantly torn between doing it right and just doing it.
The landscape of tools in the market reinforces this dichotomy. On one side, users pump CSVs into Tableau, PowerBI, or Excel or everyone is taught SQL so they can self-serve with whatever hacked together queries they can produce. The alternative with Looker, Business Objects, or a heavy ETL pipeline is just the opposite trade-off - implement and maintain a versioned data model or meticulously create perfect reporting tables that fall short as soon as there’s a follow-up question or require months of back and forth to edit.
Workbooks for self-serve freedom! or isolation? #
For all the development in BI of the last 40 years, Excel is the supreme workbook – fluid in data integration, easy to adopt, completely isolated between users, and infinitely flexible (I’m ashamed to say I’ve done pixel maps with conditional formatting in Excel). The tool is capable of ingesting and working with nearly any form of data and users at every level. Tableau, another workbook, was developed as desktop software that could handle larger data sets producing outstanding visualization. The core of workbooking is freedom. Any user can collect their own data and perform analysis, in isolation. This means users are unconstrained from the need to reconcile metrics across other workbooks and users. And the outcome is speed – users can solve their problems and move on to other questions.
Of course all this freedom comes with a cost – isolation. While users are allowed to move quickly, the lack of reconciliation means two workbooks can process and define data independently. Reusability, governance, and reliability is nearly impossible in these documents. So when reporting requires pinpoint accuracy across finance, sales, and product, the workbook’s lack of constraint means work either needs to be re-done or painstakingly reconciled. The speed comes at a cost.
Centralized BI for security! Wait, is that inflexible? #
The data modeling paradigm is about as old as the database itself. From dimensional data modeling, to OLAP cubing, to modeling languages (and back to materialization?), the core functionality revolves around manicuring both materialized and virtualized datasets, so that downstream users can consume faster, governed, reliable reporting. The monolithic vendors of the late 1990s and early 2000s (Business Objects, Microstrategy, Cognos, OBIEE, Microsoft SSRS) were built for slow, expensive early transactional databases, and building core financial reporting. Changes to reports often take months, and require specific expertise across the database, ETL services, and the modeling layer.
But this rigidity comes with some benefits – security and reliability of metrics [that do exist in the system] is unmatched. Centralization and complex user management means lineage and auditability for any dashboard. And while inflexible change management often frustrates end users, when publishing data to marketplaces or building core financial reporting, this rigidity is a feature. The systems don’t suffer the same reconciliation challenges of the workbook environment, you just may have to wait to get the data you need.
Bringing it together. #
Great teams opt to live in both worlds – a diaspora of spreadsheets and queries for ad hoc analysis sitting alongside an inconsistently maintained ETL process and data stack. Isolation and speed for ad hoc analysis and open exploration, alongside governance and reliability for simple use cases, core reporting, and mission critical use-cases.
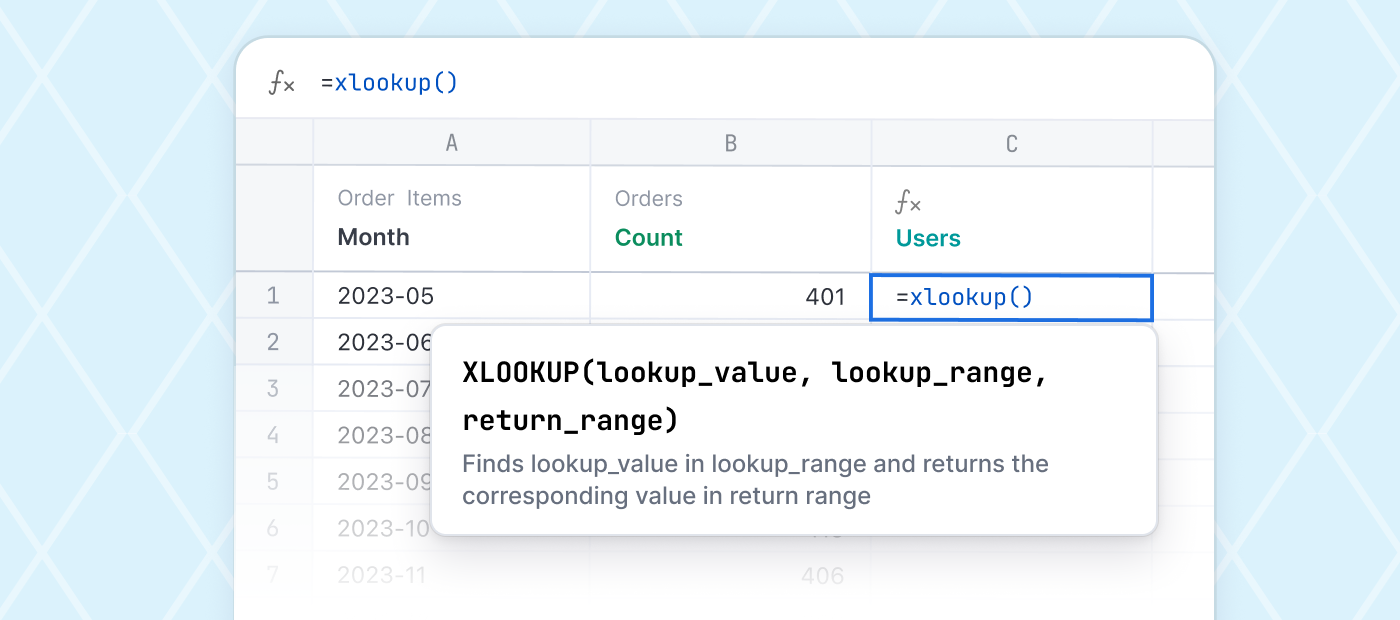
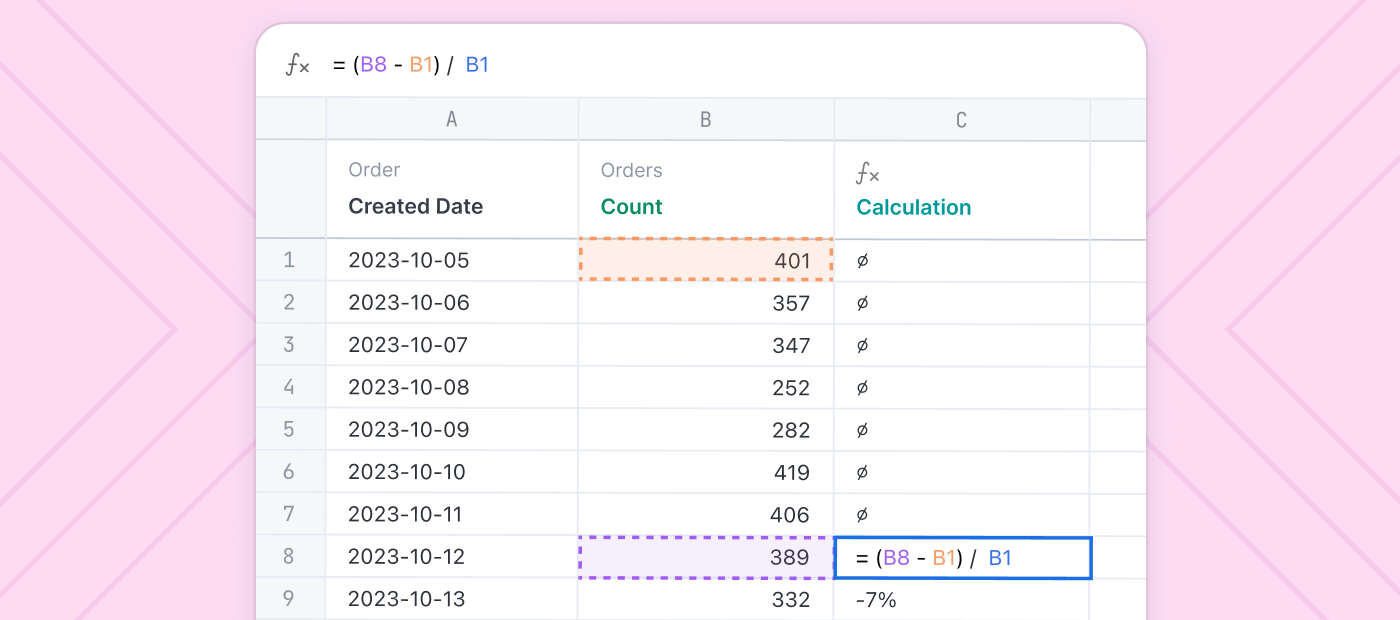
But the current paradigm means both sides cannot work together. Isolated analysis is just that – forgotten islands of data detached from other users, often lost to time. Meanwhile the core data model locks users into a rigid path where even the smallest deviation may be impossible. Why can’t users start in isolation and choose to integrate into core models later? Or start with robust data models, but reach into the SQL for quick changes or to ask the next question? Or even fold together spreadsheet data, custom SQL, and core reporting all at once?
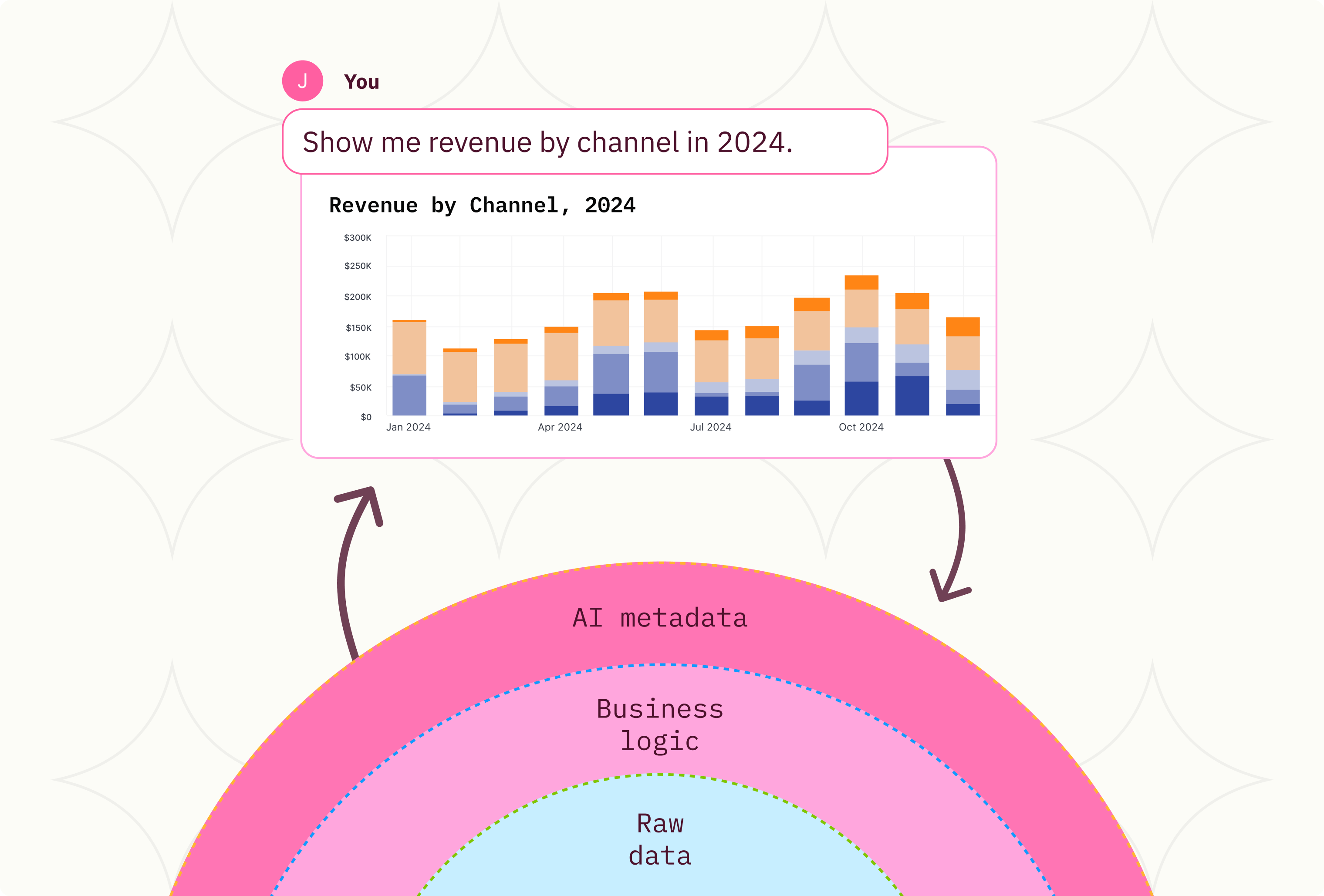
We’re building this pragmatic balance in Omni. Direct access to your database to move quickly, but supported by a data model that grows and develops as users query. And rather than a data model that locks users into modeled concepts, now users can trivially compile modeled queries, then edit and customize raw SQL, and even quickly deploy those changes back into the data model.
If this sounds like an interesting problem to solve, we are hiring for all engineering roles. Join us to build the business intelligence platform that combines the consistency of a shared data model with the freedom of SQL.