Recently, I was asked what makes Snowflake so successful as a business, and my answer is a pretty simple one - they make life easy for data people.
Historically, data teams needed to think long and hard about dimensional data modeling, database tuning, and even database sizing. Not to say these problems went away! Folks should still be doing all of these, but Snowflake offered an alternative - spend a little money, configure some settings, and the problems can disappear (pro tip - there’s still work to do here, but you can scale up → optimize → repeat).
In many ways, Snowflake built the ‘easy’ button for data warehousing. Rather than spending time configuring sort keys and distribution keys in Redshift, we got elastic compute at a decent cost, with friendly SQL. The result has probably been the most impressive growth chart in enterprise software ever:

Source: Public Comps: Snowflake S-1 & IPO - Teardown, 2020.

Source: FORM S-1 REGISTRATION STATEMENT, Snowflake Inc., 2020.
Needless to say, if you’re reading this you probably didn’t need these charts to believe Snowflake is successful, but it’s still just impressive to see.
So beyond loving to analyze business data and financial models to understand what makes companies just work, why do I care?
Using Snowflake and Omni #
First off, Snowflake is currently our most popular data warehouse connection in the Omni BI platform.

Additionally, Snowflake also serves as the foundation for our internal logs analysis. In the same way Snowflake takes some of the weight out of dimensional data modeling, semi-structured data like JSON has become trivial to analyze with Snowflake - making life a little easier for us too.
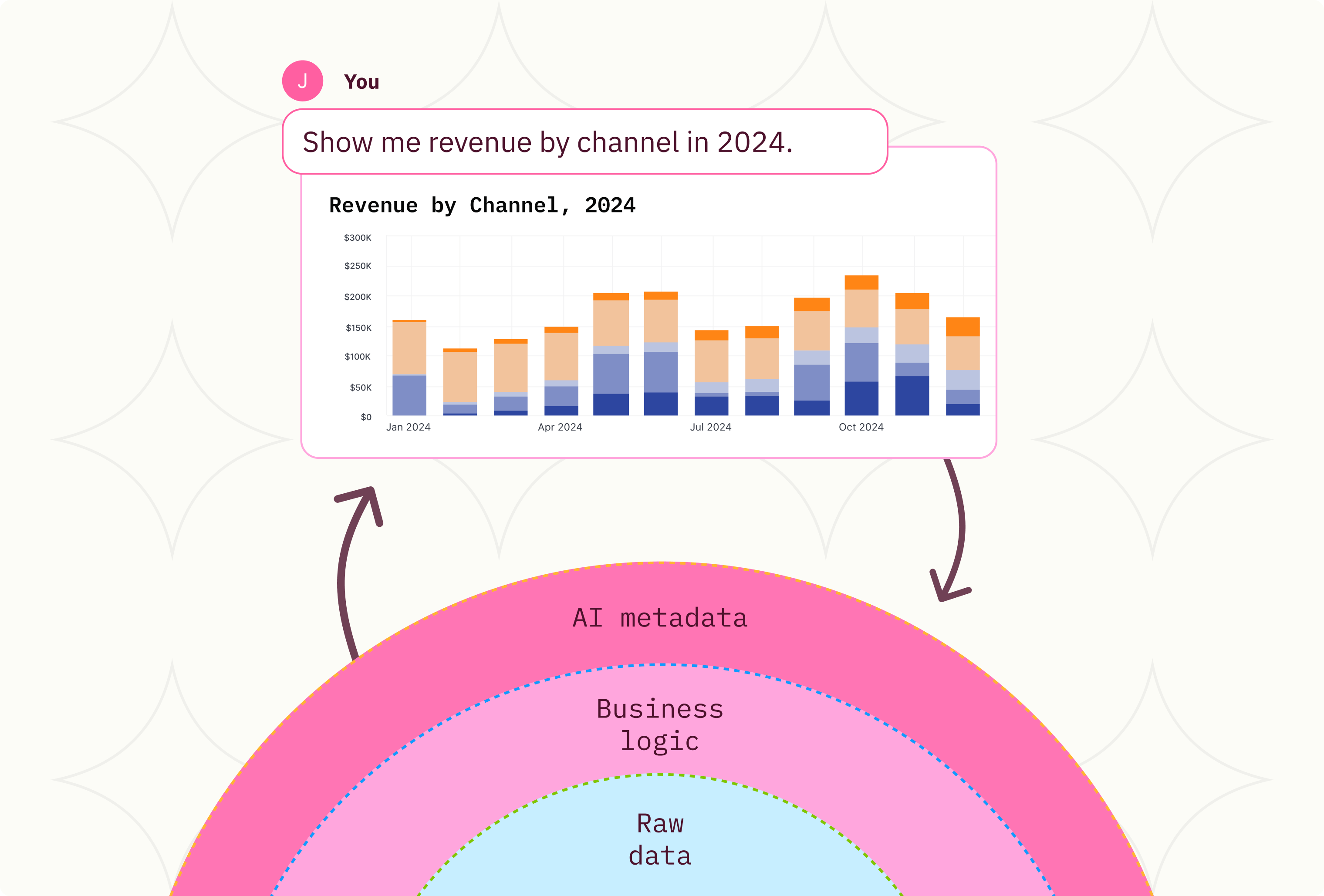
For example, here’s a quick look at how we approach monitoring at Omni piping our Docker logs through S3 to Snowflake:

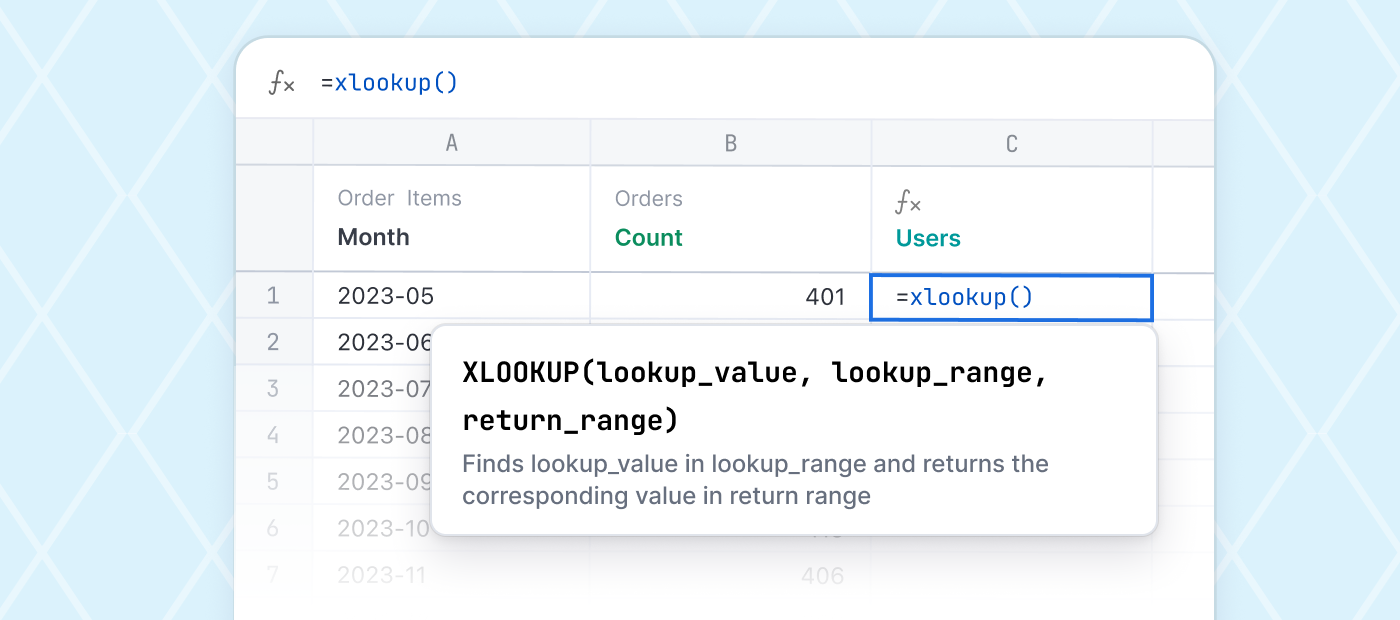
Once the logs have landed, it’s all pretty quick. JSON can be unnested in a couple of clicks using Omni and Snowflake to flatten and model the complex nested structures. Here are a couple of example events from our Demo environment:
While not terribly helpful in this form, with a little munging, we get a functional structured query model almost instantly. Some examples of what we put together:

Sampling of query execution time (average / median) with query count gives us customers to target for that query optimization I mentioned that we could ignore (since not everyone is using Snowflake yet).
Here we are monitoring 500 Errors to track down problematic code paths:

Snowflake makes a lot of things easier, and I hope this gives a nice flavor of the unlock you can get by simply dumping your semi-structured data in Snowflake and exploring with Omni. Stay tuned, soon we’ll show more of our internal use cases - both from business and technical how-to perspectives - around Github, Salesforce, and usage tracking down the line.
P.S. - If Snowflake made your life so easy that you‘re attending Snowflake Summit this week and want to meet up, let me know.