Earlier this month, Daniel Mintz and I talked with about 15 other data leaders from the First Round Network. We spoke with them about building data stacks (and more). Here is a summary of the conversation. #
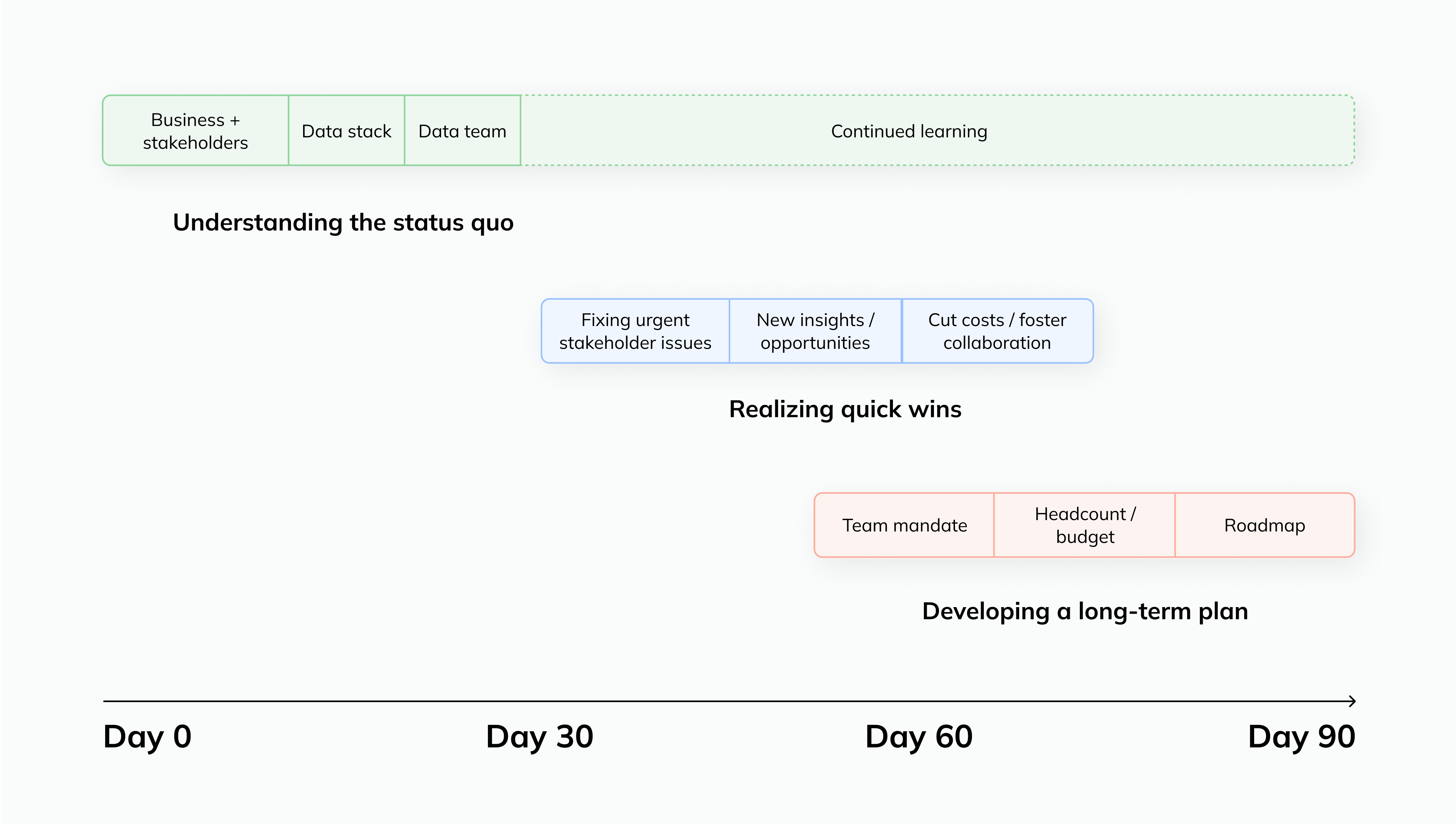
Summary of suggestions for building a data stack. #
Be pragmatic. Build what you need for the team on hand and the business goals right now. Know that you will evolve and adjust your stack as the business needs change. Remember that data teams need to serve the company – so think hard about always doing that, and align your data stack and team goals to what the business is working to achieve.
The right places to start. #
Avoid tackling everything at once by incorporating too many tools or components - data movement, a warehouse, dbt, and BI are the right starting point.
Focus on a business case that can do something measurable - reduce costs, save time, increase revenue - and build from there.
Think of your data stack as an MVP product. Just like building a product, start with the minimum viable tool set.
Embrace modularity and the ability to add new elements over time is desirable. Don't waste time trying to perfect everything from the start.
You will learn more from using 2-3 tools in the three months than from discussing or theorizing on a whiteboard.
The database. #
Regarding performance, all the popular cloud data warehouses are primarily interchangeable unless you're pushing the limits of what's possible.
Consider the pricing models, which vary based on the shape of your data, the speed of updates, and the volume of data stored. While optimizing cost is important, it's hard to know the exact price. Still, all options will provide significant performance improvements compared to querying a replica of Postgres or MySQL once data starts growing (i.e., events).
Starting with a replica of Postgres is fine, don't shortcut and use the production database. I have taken it down a few times, and that isn't good.
Yes, there are a lot of tools to choose from, and you only need to use them some right now. #
The data stack is improved due to its modularity. Vendors recognize the importance of interoperability with different parts and versions of the stack. This allows for a smoother transition as the stack grows and matures one piece at a time.
Your data environment will change as the company scales, and that's good. Early on, speed and availability are often more critical than repeatability and perfection. Data quality, reliability, and cost management can be focused on as you scale. You don't need to build your future stack now, but have it in mind with your current toolset.
For example, start with a simple transformation in your BI tool. At some point, you'll want more control and will move to dbt. And then, you will need it to be responsive, and you will want to run it on a different cron. So you move to Airflow. Make these transitions as needed, but do it when it makes sense.
Do you decentralize or centralize the analytics team? #
The shape of the analytics team may not be as crucial as ensuring that all the necessary skill sets are covered because gaps in skills can lead to difficulties and inefficiencies.
Data is a team sport regardless of how the team is organized. As such, there needs to be coverage for all aspects of the data pipeline, from data engineers who handle the start -- to analytics engineers who restructure data for use -- to analysts who provide insights for the company.
And, please, leverage the subject matter experts who understand the needs of departments such as marketing, sales, or finance. Too often, an analyst will spend a lot of time diving into data to find insights to give to sales or marketing, but if they had leveraged someone on those teams, the insights would have been found much quicker (and they still would have learned a ton.)
When to stop fighting the addition of point tools and accept them? #
The adoption of new tools is a sensitive issue, especially when it comes to replacing an established one. The key is to have a clear reason for the change, whether to answer questions that can't be answered with the current tool or to resolve misalignment in business understanding.
People are the most challenging part of the change, not the technology. You want the adoption of new tools to be driven by the people who will use them, not imposed upon them. Changing tools can cause resistance, especially if it involves taking away a tool that has been used for years and works well for a particular purpose. The people using the tools will likely find a way to work around you if they don't see the value of the change. So, for example, if you are fighting to get Excel out of the hands of finance, you're never going to win–just give up. But if it's marketing, and they really like the built-in reports in Marketo or Salesforce, you can probably show them a better way with tools with more connected data.
Be careful of heavily manicuring things underneath the BI layer. #
Things under the BI layer are usually hidden, or teams are unaware that others teams make changes. For example, if changes are made in the middle layer, but the data engineers do not know about it, that will cause them problems.
Make sure everyone knows what's happening and why it's happening. Have explicit agreement between all the data and analytics engineers to avoid issues.
The goal is not to structure data perfectly but to solve a business problem. It's essential to work backward from the problem being solved.
What about batch vs. real-time data? #
The reality is that building a system with a minute's latency is way easier than building one with a microsecond latency.
To understand what you need to build, ask questions until you uncover the actual need.
First, ask, 'What do you mean by real-time?' and dig from there...
'What if you get it every hour?' Most of the time, they say, 'Oh, that's great.' Because that is better than the weekly report they are getting now. If they say 'No,' ask, 'What about 10 minutes?'...if... 'No,' then...'What about a minute?' and they will probably say 'Yeah!'
How to judge when manicuring gets out of hand and becomes unscalable. #
Find tools that make the transition from a one-off project to a critical part of the business seamless without starting from scratch every time.
It is ok to start by doing really unscalable things first; you'll learn from it. For example, today, I was trying to create a usage metric and wrote horrific SQL, but it made the chart I wanted.
Over time, as the charts get used, I will need to make performance decisions about quality, how reliable it is, and how much people are allowed to touch it. Then I will clean it up.
Think about how people use the data and how much you will have to keep touching it. Using a BI tool and changing a field to do a timezone offset or something like that is straightforward. Once you've lifted it out into Airflow or Prefect, fewer people can touch it.
Show the value of data teams and data tools. #
To show the value of the data team and/or tools, find and solve a problem that makes the business money or saves the business money. It is essential to think of data as a customer service job. Make sure to think about the data team serving the business and what the business needs.
It doesn't matter if the data and pipelines are beautiful if the business they support is not improving. Instead, focus your data work so that things like marketing spend is more efficient and the company is making more money or saving money. Think like the business owner, but also think about who your customers are and what makes them happy – if the marketing leader loves you, if the sales leader loves you, if finance loves you, you're doing great.
Let us know if you’d like to give it a try! We look forward to your feedback.