Over the last 15 years leading data teams, I’ve seen just about every flavor of BI rollout — from rigid, top-down modeling to completely free-form, raw data environments.
I’ve watched plenty of teams fall into the same trap: they wait too long to get value from their BI tool because they feel like everything has to be perfect first.
Now, as a partner to data teams implementing a new BI platform, I sometimes hear this mindset pop up. A team is excited about the product — the flexibility, the shared data model, the self-serve access. But then they look at their existing environment, whether it’s SQL-based dashboards or a thick layer of curated data marts, and think:
“To get the most out of our data, we’ll need to rethink our whole approach.”
That’s a fair reaction – but it’s also not true!
The myth of “Day 1 readiness” #
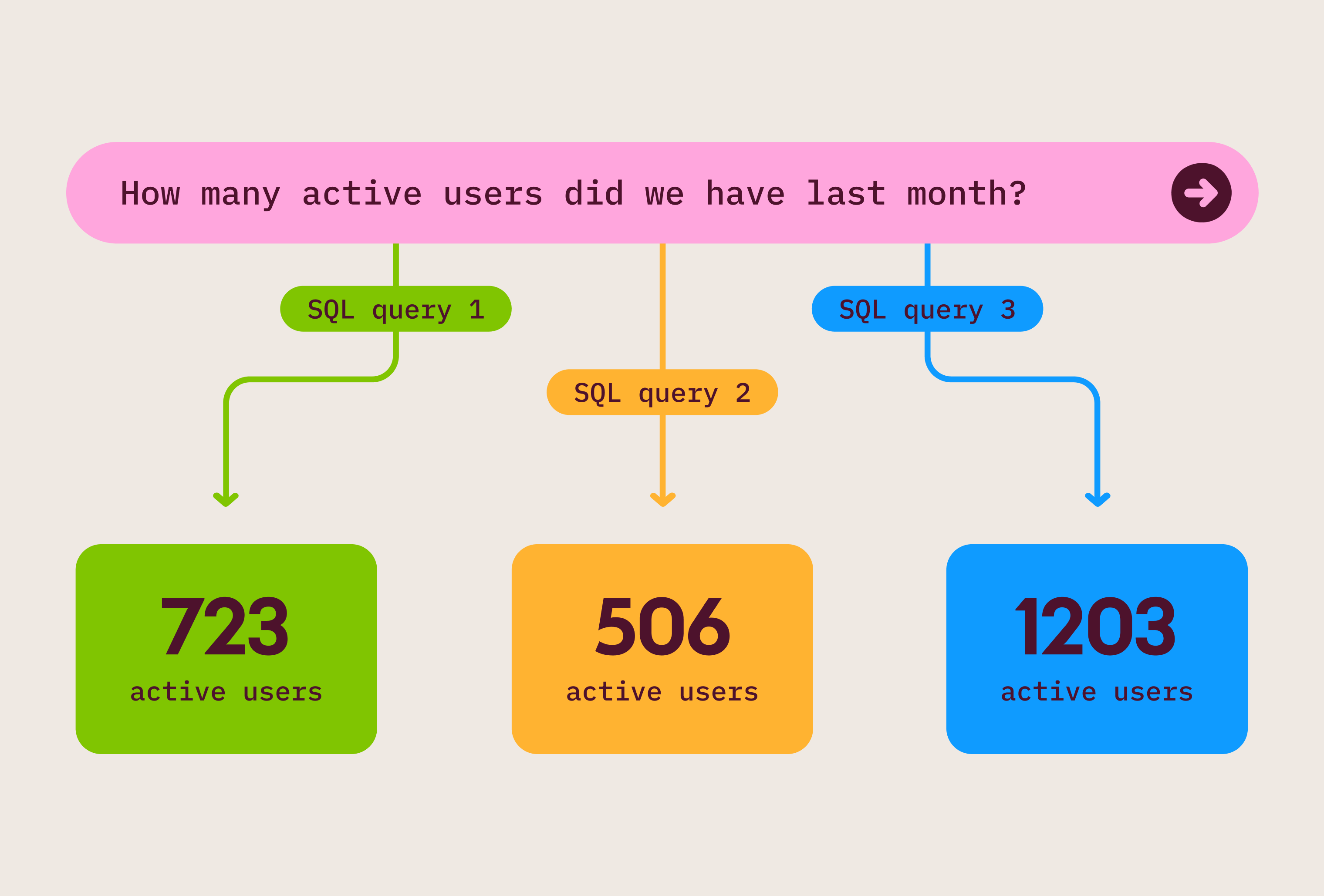
There’s a common (perhaps unspoken) assumption in the BI world: to use a tool well, you have to abide by the tool’s philosophy. For Looker customers, no data model means no data exploration. Tableau customers have to have “gold” data prepared to create nice visualizations. In Metabase, users have to learn SQL – or the data team has to maintain libraries of reusable SQL queries.
The onset of dbt added another layer of complexity. Do I create all my models upfront? Do I keep all my business logic in my BI tool? How do I keep up with ad-hoc exploration?
So it’s natural for some teams to assume that if they don’t manage their data “in the right way,” they’ll miss out on something.
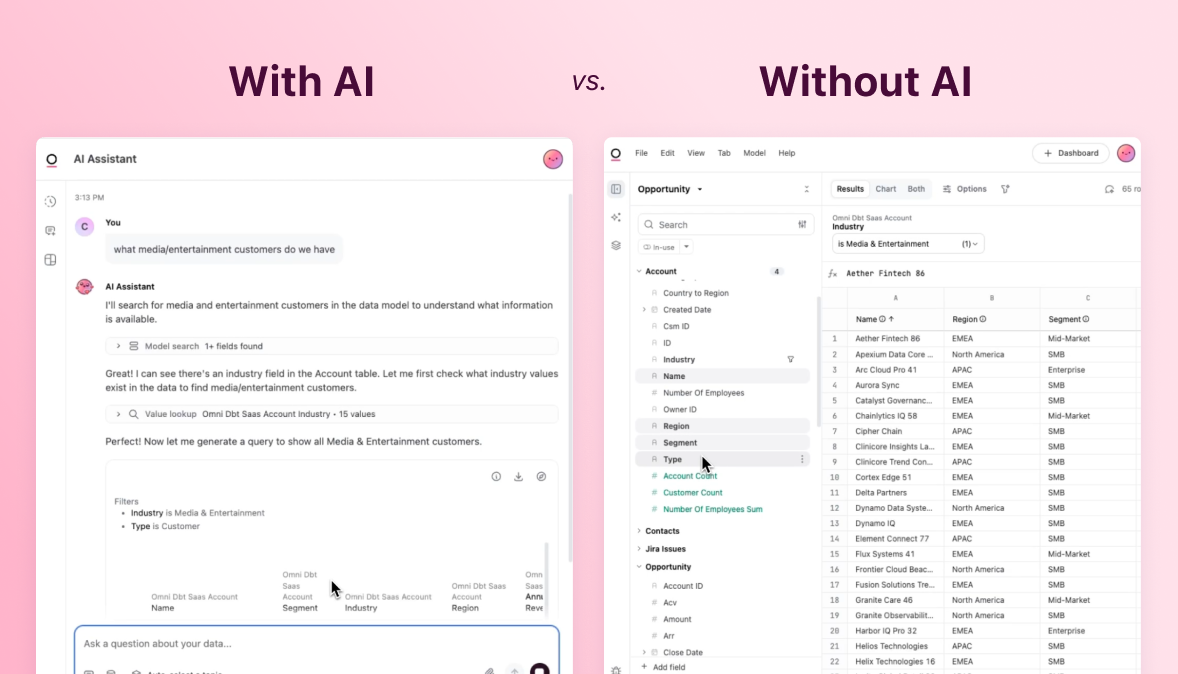
But Omni is designed to work with you, not force you into a particular way of working. You can absolutely drop Omni on top of your existing setup and start opening up self-service right away. Business users start analyzing data on their own, giving your data team the chance to observe how your organization uses data without slowing anyone down in the process. Then, over time, you can optimize and fine-tune your setup to build a high-quality, long-term data model that truly helps your organization use data and AI better.
Immediate wins, without refactoring upfront #
Here’s what this looks like in practice:
Get going with self-service immediately. You connect Omni to your data warehouse. If you’ve got existing data marts or dbt models, you can start building Topics (curated datasets) to reflect them. Or, if you’re used to running raw SQL, you can build Topics off of saved SQL queries and create reusable joins. Either way, this often only takes a few clicks.
Then, your business users can start exploring these “safe” datasets without having to worry about the underlying SQL or joins. It’s all available to analyze freely with familiar Excel syntax, our point-and-click UI, or even AI. Without refactoring a thing, you’re able to give your team more flexibility to analyze data.
See how your team uses data. You start getting insight into what users are looking for with in-product analytics, like what fields they care about, which joins they expect, and which dashboards are driving real decisions. You begin to see where there’s overlap across dashboards and duplicated logic in workbooks.
Think, plan, act. Now that more users are self-serving data, you can do less ticket-taking and actually think strategically. Where can I centralize business logic? How can I make queries more performant? Can we extend access to this data to our customers?
Maybe you consolidate a few Topics into one, implement aggregate awareness to optimize query performance, create a hub-and-spoke model, launch embedded analytics, or many other refinements. In any case, you can confidently create and execute a plan grounded in real-world understanding of your organization’s data needs.
Iterate as you go to de-risk your work #
Unfortunately, no matter how much planning you do upfront, your initial data model will never be perfect because your data and needs will constantly evolve. This is why we've built flexibility into the product — so you can adapt without breaking things.
Iterating could be as simple as changing field names or updating dashboards. It could also lead to a broader rethinking of your modeling approach, even beyond what you thought was possible with previous tools.
You may well be modeling something today that doesn’t even need to be modeled, and can instead be accomplished with Excel calcs, filter by query, and xlookup. These small changes can lead to big improvements, including less compute in your data warehouse and fewer complex dependencies upstream.
Or, maybe you were previously using raw SQL to query everything. With Omni, building reusable metrics, joins, and Topics could lead to more consistent results and faster performance. You can also use our dbt integration to push logic down to your database.
Building your data model iteratively lowers the risk of modeling too soon — and raises the ceiling on what your data model can actually achieve.
Let’s see how this works in Omni #
In the demo above, we show you how to start analyzing immediately from a new database connection; quickly curate datasets for self-service; and then go deeper in the data model over time to optimize based on what your team actually uses — including how to add additional context for more reliable AI.
Not a tradeoff, but a flywheel #
You don’t have to choose between fast time-to-value and long-term model quality. You should be able to have both:
Fast self-service access on day one, even on top of messy or rigid data structures
High-quality modeling over time, guided by how your team actually uses data
You’re not forcing yourself onto a narrow path and hoping it works. You’re observing, adapting, and improving — without sacrificing momentum.
The best time to get started isn’t after a six-month modeling sprint. It’s right now, with the data you already have. That’s why we’ve seen teams like Buzzfeed and large retailers migrate large data environments in rapid time.
Connect your data, give your users access, and let the usage patterns show you where to focus. You'll start getting value right away — and when you’re ready to invest in your model, you’ll have everything you need to do it right. If you’re curious to learn more, we’d love to show you.