Every organisation strives for clarity based on data. When people agree on what reality looks like, it’s easier to decide what to do next.
To achieve that clarity, everyone in your organisation needs to be able to access, understand, and trust the numbers. But creating that shared understanding requires more than just correct metrics – you need a way to align on what the numbers mean. That's where the semantic layer comes in, which I think of as:
A governed set of metric definitions and business context — formulas, filters, grain, time logic, currency — that queries resolve against.
So where should this business logic live? Should the semantic layer reside in your data warehouse? In a transformation tool like dbt? In your BI tool? There’s never been a clear consensus — but as more companies adopt and rely on AI, the need for a shared, visible semantic model that understands the context of your business has never been more clear.
I've led data teams for 15+ years and seen what works and what doesn’t. Based on my experience, I believe the semantic layer belongs in your BI tool.
To put my thinking simply: if you want your data to reflect the reality of the business, then your business logic needs to live where people learn, investigate, and make decisions — the BI tool. This helps drive organisational data clarity by doing three things:
Creates shared context everyone can see
Enables fast iteration and updates
Standardizes battle-tested, consistent metrics
I’ll explain my thought process below. Before getting into it, I want to acknowledge that every team and business has different needs. That’s why we’ve built integrations and workflows to support our customers in capturing and using their business logic wherever it makes sense for them — even when that’s outside of Omni.
With that in mind, let’s dive in.
Transparency = trust #
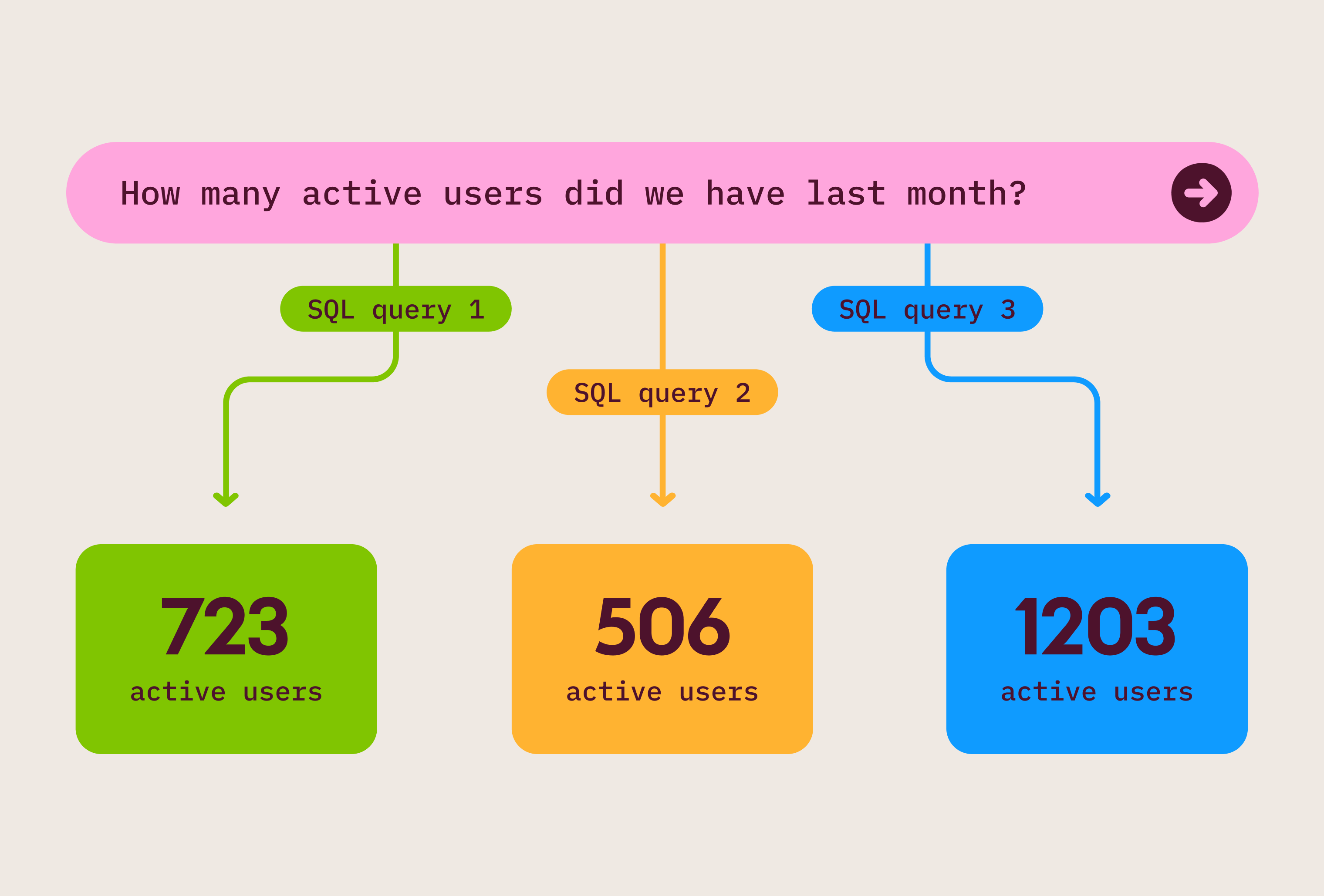
Imagine your CFO, a product manager, and an analyst are (heatedly) debating quarterly revenue numbers, and each presents slightly different figures. I’ve seen a version of this conversation many times; the conversation stalls, and no one can make a decision because it’s unclear which number is “right.” Trust in the data erodes.
This happens when business logic lives out of sight. You can define the “gold” version of revenue upstream in your warehouse, but if your VP of Sales can’t see how it’s calculated — what filters were applied, whether churned customers are included, what currency you’re in — they won’t use it or believe it. Unintentionally, they’re most likely to fall back on what they know and trust, which is probably built on extracts and spreadsheets. As a result, alignment breaks down. The “gold” version no longer makes sense to them.
AI doesn’t magically solve this; it raises the stakes. If your product manager doesn’t know what “Product Usage” means, or your CMO can’t tell whether “Conversion last month” is based on opportunity creation or close date, an AI chatbot returning the “right” number will still feel like a black box. People won’t trust the results, or worse, they’ll make decisions based on the wrong information.
Trust comes from visibility. By embedding the semantic layer in your BI tool, everyone from the C-suite to the front-line workers can see and understand the definitions behind the numbers. They don’t need to know every transformation step. They just need to know the numbers they’re acting on mean the same thing to everyone.
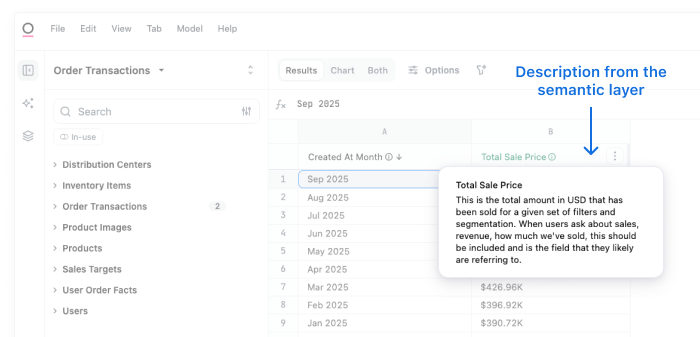
Keeping up with the business #
Once people understand and trust the numbers, something important happens: they start contributing back. Leaders, managers, and frontline employees bring their context to the table and push to make sure metrics keep reflecting how the business actually operates. Trust opens the door to collaboration.
But the business reality is constantly shifting. New products launch, sales motions evolve, markets change. If your semantic layer can’t keep pace, you’re left with definitions that describe yesterday’s reality, not today’s.
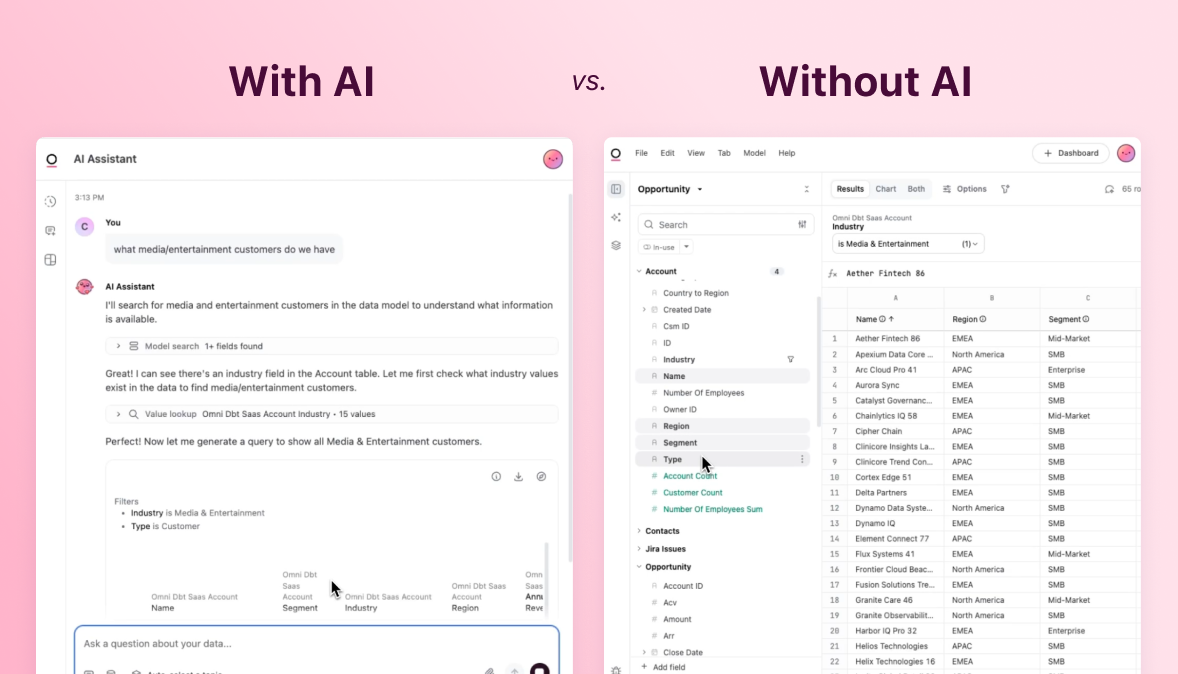
That’s another reason the semantic layer belongs in your BI tool: it’s where users are most likely to make updates in real-time. For most people across the business, BI is the primary interface for accessing and working with data. So when someone needs to redefine a customer segment, test a new engagement KPI, or adjust a revenue model, they can make that change in context — and see it reflected immediately. That speed and visibility helps the business stay aligned as things evolve.
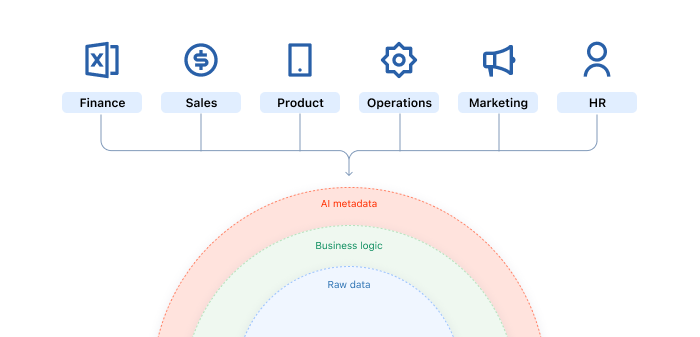
Contrast this with an upstream semantic layer in a transformation tool, headless BI platform, or data warehouse. Those layers are built for precision and stability, which is perfect for cleaning raw data, but far too rigid for every metric. If you attempt to capture everything upstream, the result is a lag: the business learns something new, but the data model doesn’t catch up until weeks or months later. By then, people have learned that the “governed” data in their BI tool can’t be trusted.
For example, let’s say your company agrees that customers who downgrade to a free tier should be counted as churned, not active. That subtle change has huge ripple effects in retention reporting. Upstream model changes typically land weekly or bi-weekly, which creates drift — like when board metrics show one number while frontline dashboards show another. BI semantic changes can land same-day, ensuring everyone gets the update immediately and preventing a misreported retention.
An obvious question may arise here: does this mean everything needs to be modeled in your semantic layer? What about dbt and other transformation tools? I’ll touch on this next.
A starting point for warehouse transformations, customer-facing analytics, and applications #
When metric definitions are debated and refined in the BI layer, they harden into canonical standards that capture insights from throughout the business.
These metrics become an ideal backbone for other applications. Once they’re stable enough, it’s often useful to promote those from the BI layer down into your data warehouse. This can help speed up query performance and make them accessible to other parts of the data stack — beyond the BI layer. Not only that, they can start to be folded into product evolution and customer-facing analytics.
For example:
A SaaS company might show customers their “Active Users” in the Admin section of their app. If that metric has been tested and agreed upon internally in BI (say, “active” = 3+ logins per week), engineering then hardcodes that definition into the product. This ensures customers see usage numbers that line up exactly with what the internal team reports.
Suppose you promise customers a 99.9% uptime SLA. If the internal definition of downtime hasn’t been aligned across ops, product, and finance, publishing it externally could create disputes and mistrust. BI is the proving ground – use the semantic layer to learn about your SLA variables, stress-test definitions, bake it into the app, and then release.
Without a semantic layer in the BI platform, it’s difficult to get to this point. Metrics may get codified too early in upstream pipelines, before they’ve been vetted against real-world business needs. By contrast, the BI semantic layer gives you a safe space to “prototype” and test definitions with business stakeholders before exposing them to customers. It’s the proving ground — learn about your SLA variables, stress-test definitions, bake it into the app, and then release.
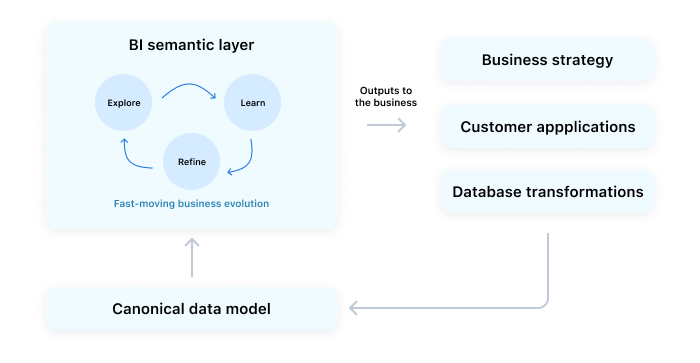
A flexible but governed BI semantic layer #
There’s certainly a time and place for more robust, “universal” semantic layers that live outside of your BI tool. We believe that semantic models should be grounded in how your business actually works — and flexible enough to move between systems so you don’t need to choose between visibility and interoperability.
Some definitions should be established upstream early, like heavy transforms that significantly impact performance or core tables that many systems depend on. For example, once you've used your semantic layer to lock in what your definition of a user is, you can likely materialise that as part of your core model. We’ve written about this more here.
However, if your goal is for everyone in your business to be able to access data and make decisions, your semantic layer should be in your BI tool.
It’s not easy to build and maintain a semantic layer anywhere. You need a BI platform that can handle the complexity of your business and is flexible enough for fast iteration, but governed enough to keep you aligned. And when you’re working with multiple tools for data storage, transformation, and BI, you need interoperability so your semantic layer doesn’t become isolated. That’s a big reason I enjoy implementing Omni with customers: our semantic layer is designed to give you governance and flexibility, so you can keep it close to where the action is while also informing what’s upstream.
I’d love to hear your thoughts. Please reach out at jon.palmer at omni.co, or schedule time with our team to see the semantic layer in practice.