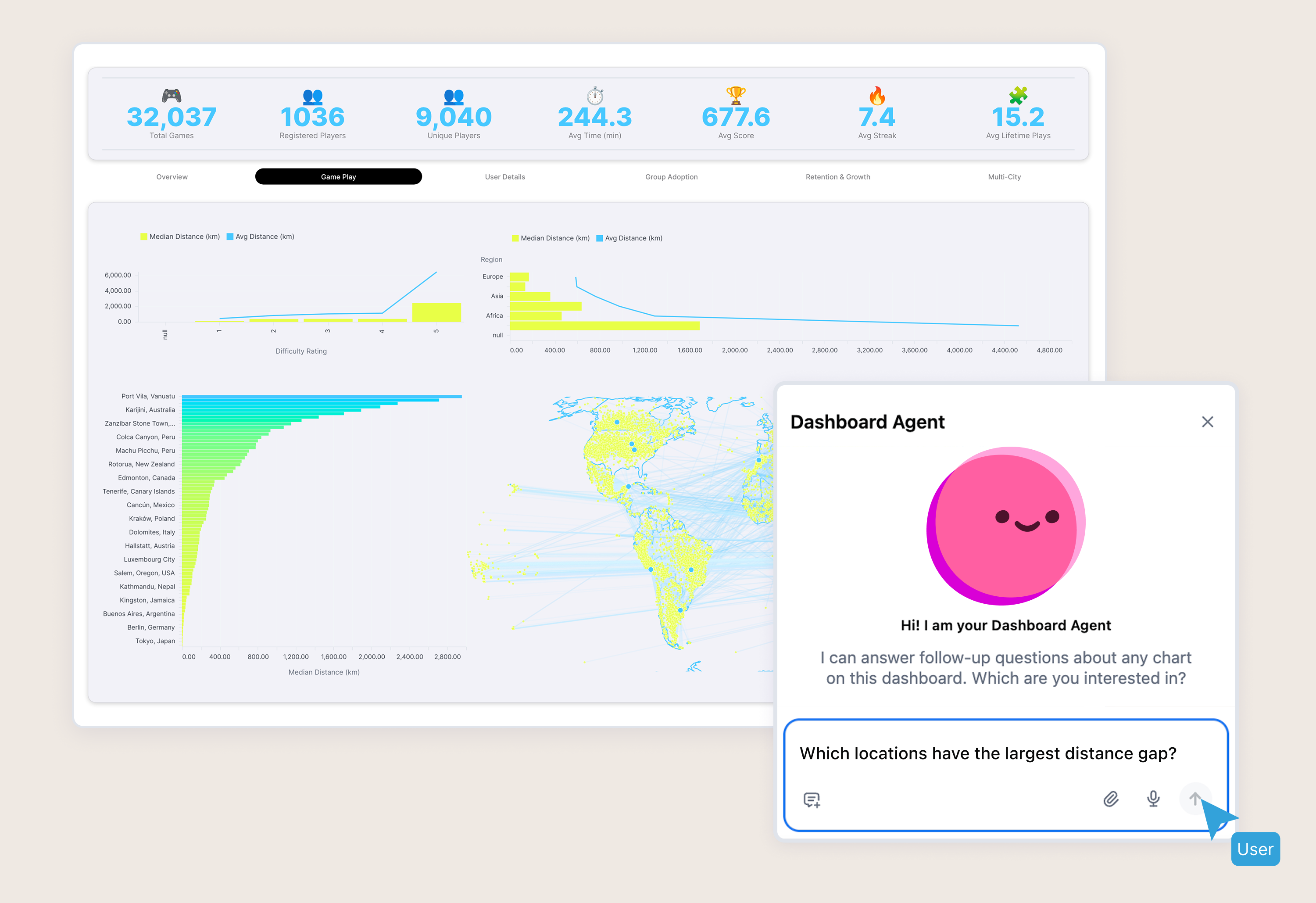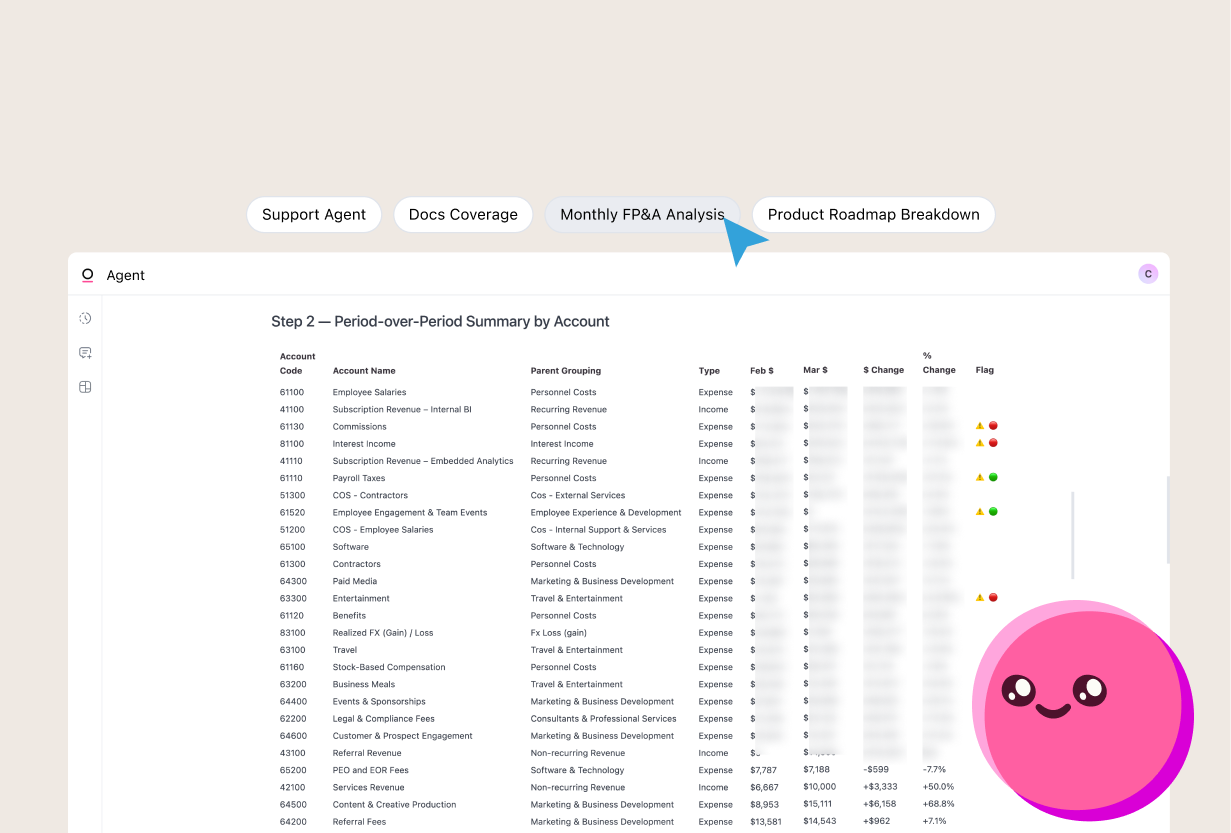
I recently jumped (back) into the BI world after two and a half years on dbt’s Solutions team, helping enterprise customers deploy dbt in their organizations. I’d gotten accustomed to the ways data engineers and analytics engineers think: they want to run their data environments the same way developers build applications.
One reason I’m excited to be at Omni now is how the platform extends that philosophy into the BI layer. With our dbt integration and software development lifecycle workflows, data teams can manage the BI and dbt development process with the rigor they want. This includes:
Branch-aware, git-integrated development environments tied to your development and production schemas
A content validator that shows which fields and dashboards would break before you merge warehouse-level changes
And a don’t-repeat-yourself (DRY) docs/metadata flow so definitions don’t drift between tools
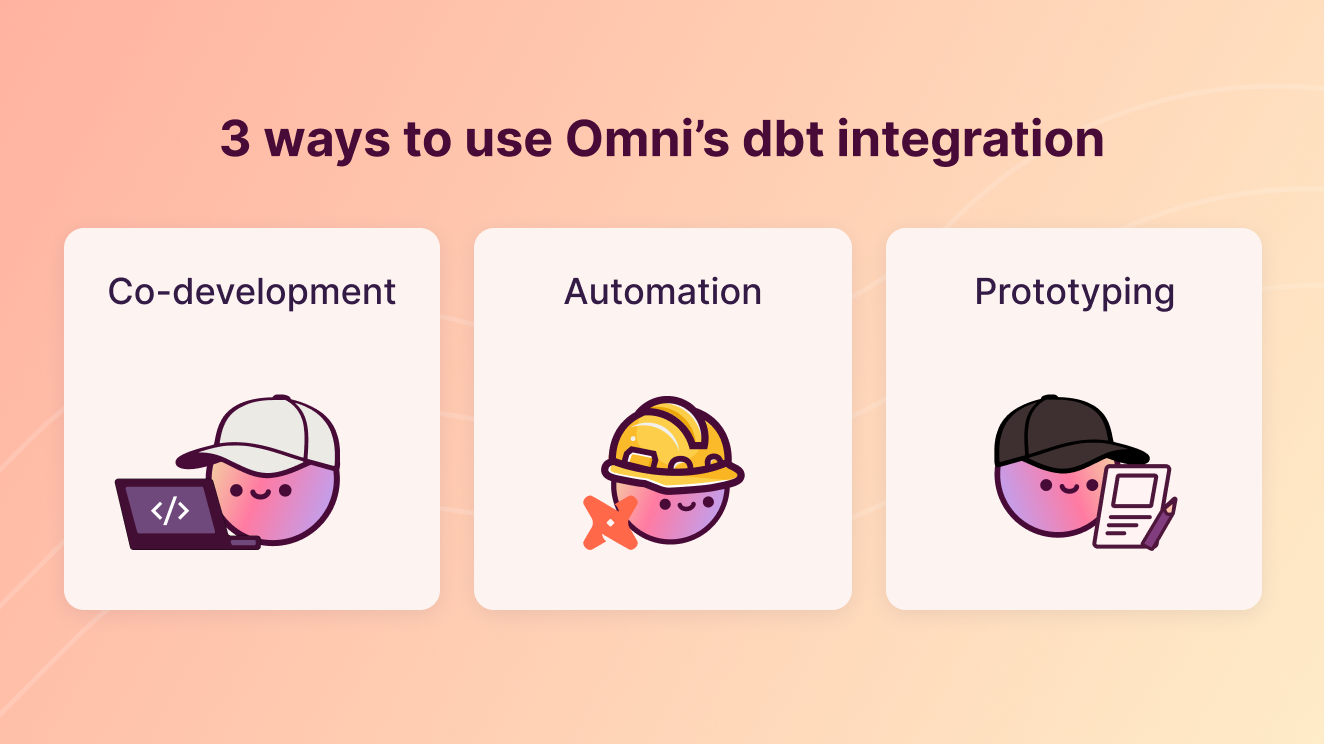
There are lots of ways to leverage the integration, but I wanted to share three common patterns our customers use to make the most of dbt + Omni:
Co-development: Development environments to test dbt + Omni together, fix any breaks, then merge cleanly
Automation/DRY: Automatic sharing of metadata between dbt and Omni helps keep definitions aligned and dbt up-to-date
Prototyping: Create virtual views in Omni, battle-test them, then swap to a new dbt model with content validation to avoid breaking dashboards
1) Co-development: Keep dbt + BI changes in lockstep #
When you’re editing a dbt model, a seemingly minor change (like renaming a column or updating a WHERE clause) can quietly break dozens of downstream charts. Without a safe place to test both sides together, teams either slow down their pace of development or risk introducing errors into content for end users.
Omni’s dynamic dbt environments give you a tight software development workflow to safeguard against this:
In Omni, point to a dev environment on a branch: Enter a branch in Omni, then choose which dbt environment to build your content off of. Your dashboards and reports now render against that environment, letting you see how changes you make in dev make impact downstream content.
Check what will be impacted: Use Omni’s content validator to see which content would break due to renamed columns, removed fields, etc.
Resolve and retest: “Find and replace” references across multiple pieces of content using the content validator to ensure nothing breaks when you merge your dbt changes.
Merge once, cleanly: You can set up your Omni schema to refresh automatically once your dbt PR lands using a git action that calls Omni’s schema refresh API endpoint. (Or, you can manually refresh your schema with a click in Omni.) Once your schema pulls in those changes, you can merge your Omni branch to update your content right away — preventing any downtime.
2) Automation: Sharing context between dbt and Omni #
Data teams often spend time building out metadata in their dbt environments, such as field and table descriptions, accepted_values, and exposures. Omni automatically integrates this metadata into the BI layer, so your team doesn’t have to manually copy-and-paste. Field-level and table-level context also automatically gets surfaced in dashboards and workbooks in the UI, so the time you’ve put into curating your .yml files translates to the end-user experience.
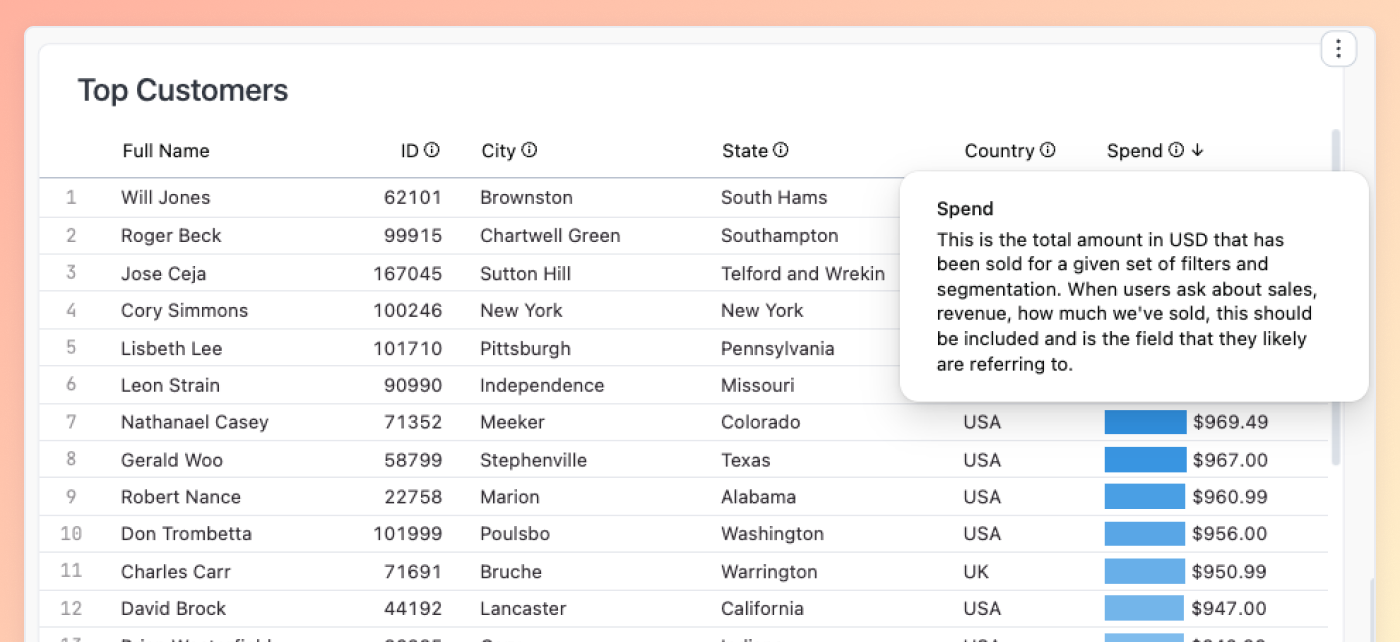
That means definitions stay consistent across tools, and people don’t have to hop between platforms to figure out what the numbers represent. For teams using dbt models as the foundation for AI analytics, this is especially useful. All the context you’re putting into dbt gets leveraged by Omni in any AI queries, helping make answers more trustworthy and grounded in your business.
Omni also lets you push metadata you’ve added in Omni back down to dbt. For example, with a few clicks, you can auto-generate YAML to define exposures in your dbt .yml file. So as you build out your Omni content, you can trace their dependencies without having to manually define each one. You can similarly do this with your field and table descriptions – define them in Omni where you’re using them most, then push them down to dbt when they’re solidified. This cuts out the manual work often needed to transfer context from the BI layer down to dbt.
Here’s a comprehensive list of the context that can currently be shared between dbt and Omni:
Field descriptions and table descriptions are automatically pulled in from dbt and surfaced to end users. Descriptions added in Omni can also be pushed down to dbt.
Exposures can automatically be generated in Omni and pushed down to dbt, directly linking to dbt models to dependent Omni content.
accepted_values, a dbtdata_testsparameter that supplies a list of possible values, are pulled into Omni’sall_valuesparameter. This is particularly useful for AI. For example, if Omni’s AI knows that your Country field only accepts “USA” and “UK”, then when someone asks to filter to “US data only”, it can match “US” to the value “USA”.Primary keys and relationships can automatically be generated in Omni based on dbt constraints, so you don’t need to manually define them again.
Omni’s dbt IDE also gives you read-only access to the files in your dbt schema, reducing the context-switching required when developing in Omni.
3) Prototyping: Go from ad-hoc Omni views to governed dbt models #
As teams explore in Omni, useful transformations will naturally emerge. Instead of leaving them as one-off queries, you can save the query as an Omni view — a lightweight, virtual transformation (like a CTE you can reference in Omni) that’s easy to reuse and simple for end users.
When a saved view needs better performance (or otherwise warrants materialization in the database), you can create a dbt model for it. Then, the content validator can cleanly remap references from the original Omni view to the new dbt model without breakage, like I outlined in the “Co-development” section. In effect, Omni acts as a “prototyping” layer to let you test what transformations are actually useful to your team before creating a full dbt model. (If you just need to edit an existing dbt model, you can do that in Omni, too!)
For example, here’s how a new Customer Fact table might follow this process:
Save query as an Omni view. An analyst creates a customer fact table by joining Orders and Customers. This gets used widely, so she turns it into an Omni view to make it easier to work with.
See how it gets used. As the table becomes foundational to some dashboards, materializing it in the database would significantly improve performance.
Build in dbt. The analyst recreates the table in a new dbt model,
fct_customers(alternatively, if you had an existing model you wanted to update, you can do so from Omni as well).Swap safely with the content validator. Use Omni’s content validator to bulk-remap references from the Omni view to the new dbt model, with schema compatibility checks and a preview of impacted content (this is where the co-development pattern comes in handy).
Retire the original Omni view. Deprecate or drop the original “Customer Fact” Omni view once everything points to the dbt model to avoid misalignment.
Governance across the data stack #
If you value dbt’s “analytics like software” mindset, Omni carries that same discipline through to BI. Together, they help teams ship trustworthy answers faster, with less breakage and less duplication.
That’s been one of the most exciting parts of coming to Omni: watching customers use dbt in tandem and realizing they don’t have to choose between speed and governance.
We're continuing to make it easier for customers to use Omni and dbt together — including building an integration with dbt's semantic layer (see a preview of what we're building here). And if you'd like to chat with our team in person, we’ll be at dbt Coalesce next week — come say hi at our pink booth and catch our session with Cribl: 700 users, 100 models, $20: Cribl’s blueprint for scalable AI-powered insights! Or, if you want a deeper walkthrough on your own stack beforehand, please reach out.