Editorial note: This blog focuses on how we built agentic analytics, but if you want to learn how to use it, check out this post for example workflows.
In order to build AI our customers could trust, we needed to take a different approach than most AI systems. Text-to-SQL models look cool in a demo, but they rarely make the jump from demo to production. We needed to build something robust and ready for the enterprise.
Our early agent was primitive — it had access to basic tools like query and summarize. We learned from how customers used this agent via our MCP Server in apps like Cursor and Claude, and it revealed something important: people wanted to ask broad, open-ended questions about their data, just like they do with general LLMs. How is our pipeline looking this quarter? Why did revenue jump last month? How are customers using AI features?
These questions span multiple datasets, and they’re rarely answered with a single query. So an agent needs to think, plan, and act with a broader set of tools. That insight became the foundation for our agentic framework, built to tackle real analytical challenges while staying as reliable and governed as everything else in Omni.
Today, this allows our AI to go past a single query and decide what to do next — whether that’s continuing an analysis, comparing datasets, investigating data for the right matches, or summarizing what it’s learned. This also opens the door for lots more exciting features and workflows.
It took lots of work and rewiring, but the payoff is pretty exciting. Instead of stopping at “here’s your SQL,” our agentic AI can orchestrate a chain of analyses to surface insights that help you make decisions and act. The result gives our AI a bit more rope (or “agency” if you will 😉) to decide how to solve a problem on its own.
Here’s a look at some of the work that got us here:
Breaking past one-and-done AI #
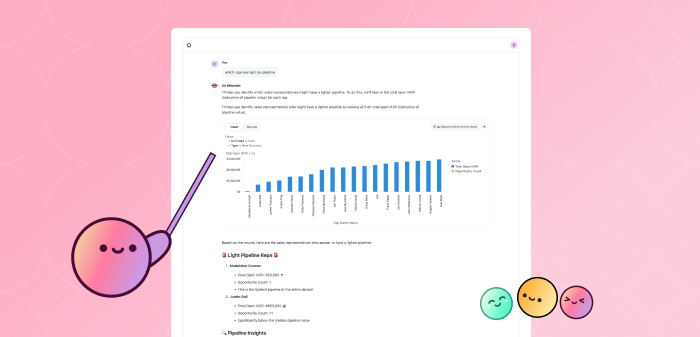
When people ask a business question, the answer is rarely the result of a single query. We saw this firsthand when we started asking our AI tougher questions on our own data:
“What percent of our users are currently using our AI capabilities?”
With the way our data is structured, this requires us to write two queries: one to find the total number of users, and another to determine users who are specifically using our AI features.
“Why did our revenue increase last month?”
Any question starting with “Why?” can almost certainly send an analyst on a wild goose chase, requiring them to slice and dice data across many queries until they find a definitive answer.
“Pull a list of all accounts with active demos from the last quarter grouped by sales rep, then summarize the key trends for me to share with the exec team.”
These aren’t necessarily asks that require queries of multiple datasets, but they do require multiple interactions with the same dataset.
These are real questions we needed to answer, and none of them could be solved with a single query. We needed to make sure that we were evolving our product to support questions like these.
At this point, we’d already helped some of our customers successfully answer these kinds of questions using an LLM with our MCP server. The key was that the LLM was intelligently coordinating our AI. It could break down the user’s question into parts, run queries to answer each individually, then summarize the results. That insight spurred us to bring the same orchestration layer natively into Omni’s AI.
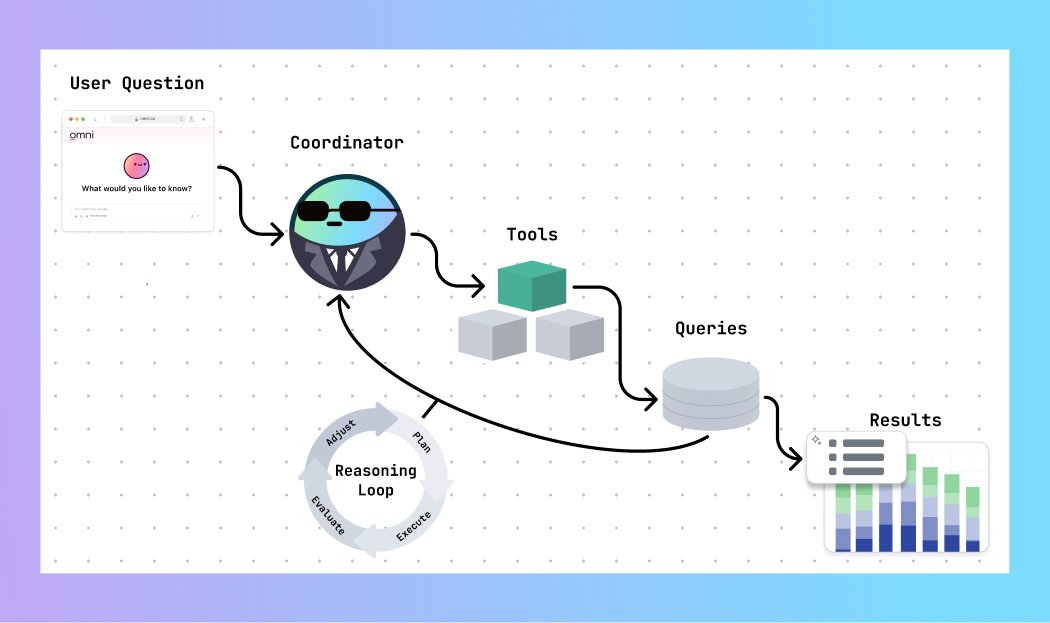
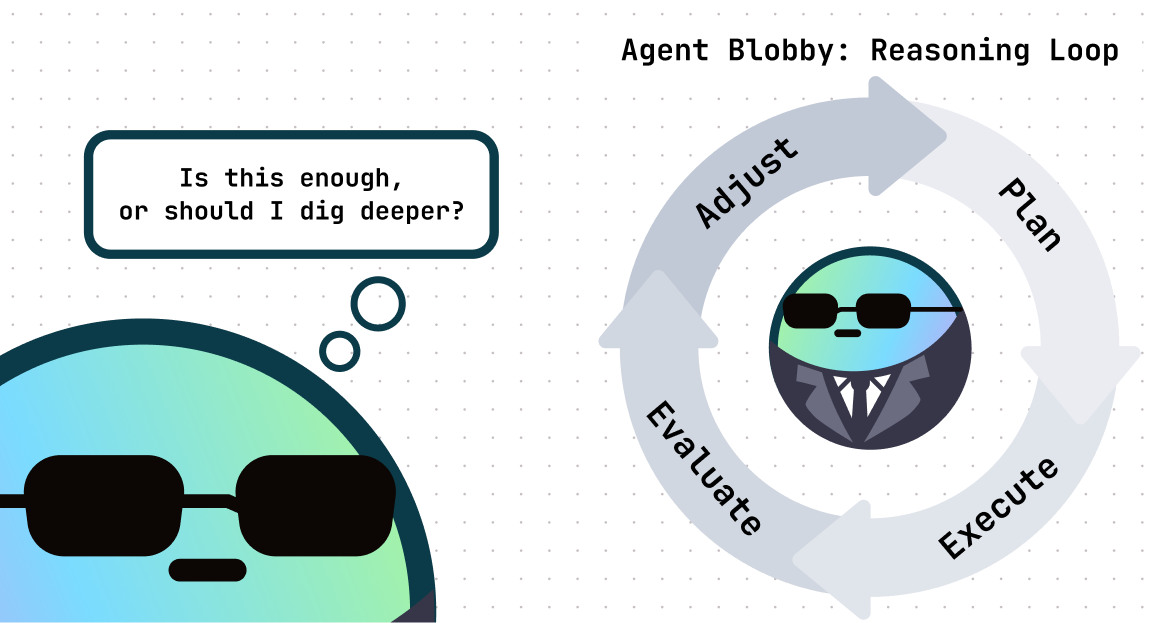
So we architected our AI to have a coordinator mechanism, which decides which tool to use next based on the question, the results, and what’s already been tried. It’s what lets the AI adapt mid-flight, retry when things break, or stop when it has something useful to show.
Once we’d built the coordination layer, Omni’s unique advantage became clear: our built-in semantic layer already enforces governance, context, and business logic by design. This is the difference between a generic LLM and an AI-native platform with built-in context. Our semantic layer acts as the intelligence backbone to teach the AI your specific business language: your metrics, definitions, and logic. Instead of guessing, the coordinator is making decisions based on a deep understanding of how your business works.
With this institutional knowledge, the agent already knows what “active customer” means, understands which fields drive revenue, and respects who’s allowed to see what. And since the semantic layer is visible to humans too, users can debug or improve the logic.
Another upside of this approach is resilience. Even when the underlying data isn’t perfectly curated, the agent can recognize when its assumptions didn’t hold and adjust its approach instead of returning an empty or incorrect result.
Our semantic layer makes agentic querying more traceable and accurate. It’s the reason our AI knows what counts as revenue, how to filter churned users, and what execs care about in a summary.
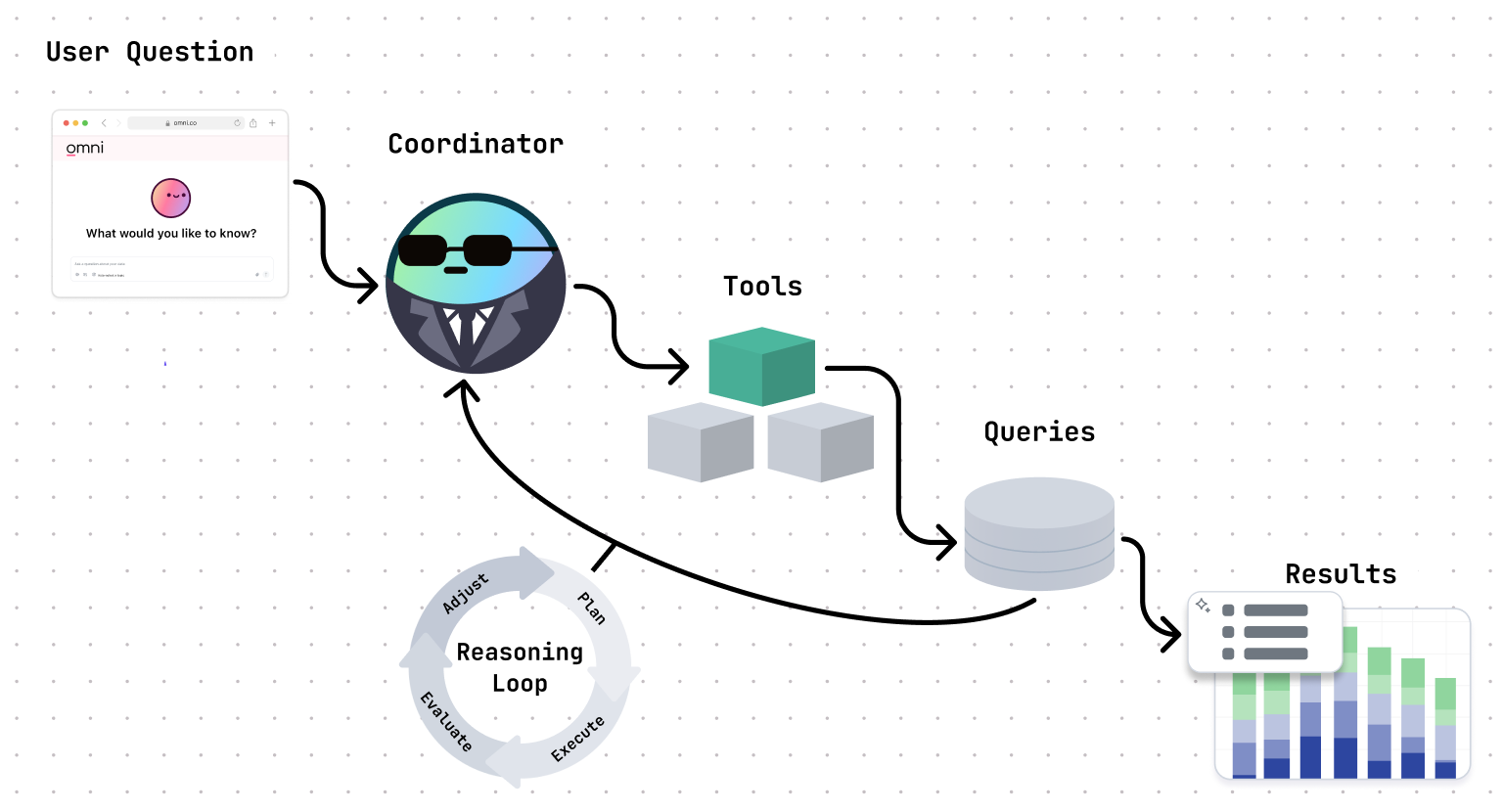
Building the AI toolshed #
Once we had the coordinator in place, we needed to organize its toolbox to help it operate as effectively as possible.
Topic picker + query tool
Inspects metadata across Topics, curated datasets that serve as the foundation of analysis in Omni, and makes an informed choice before generating SQL.
Why we built it: For questions that inevitably require you to span multiple datasets, the Topic picker helps the AI find the right combination of datasets to answer questions accurately.

Field values tool
This tool enables the agent to interpret your question, fetch the list of valid field values, and adjust to find the correct match.
Why we built it: Prior to our rework, a query could have returned no results because of an invalid filter based on a question like: “How many users are in New York?” if the system expected “NYC” as the value in that filter. This fixes that.
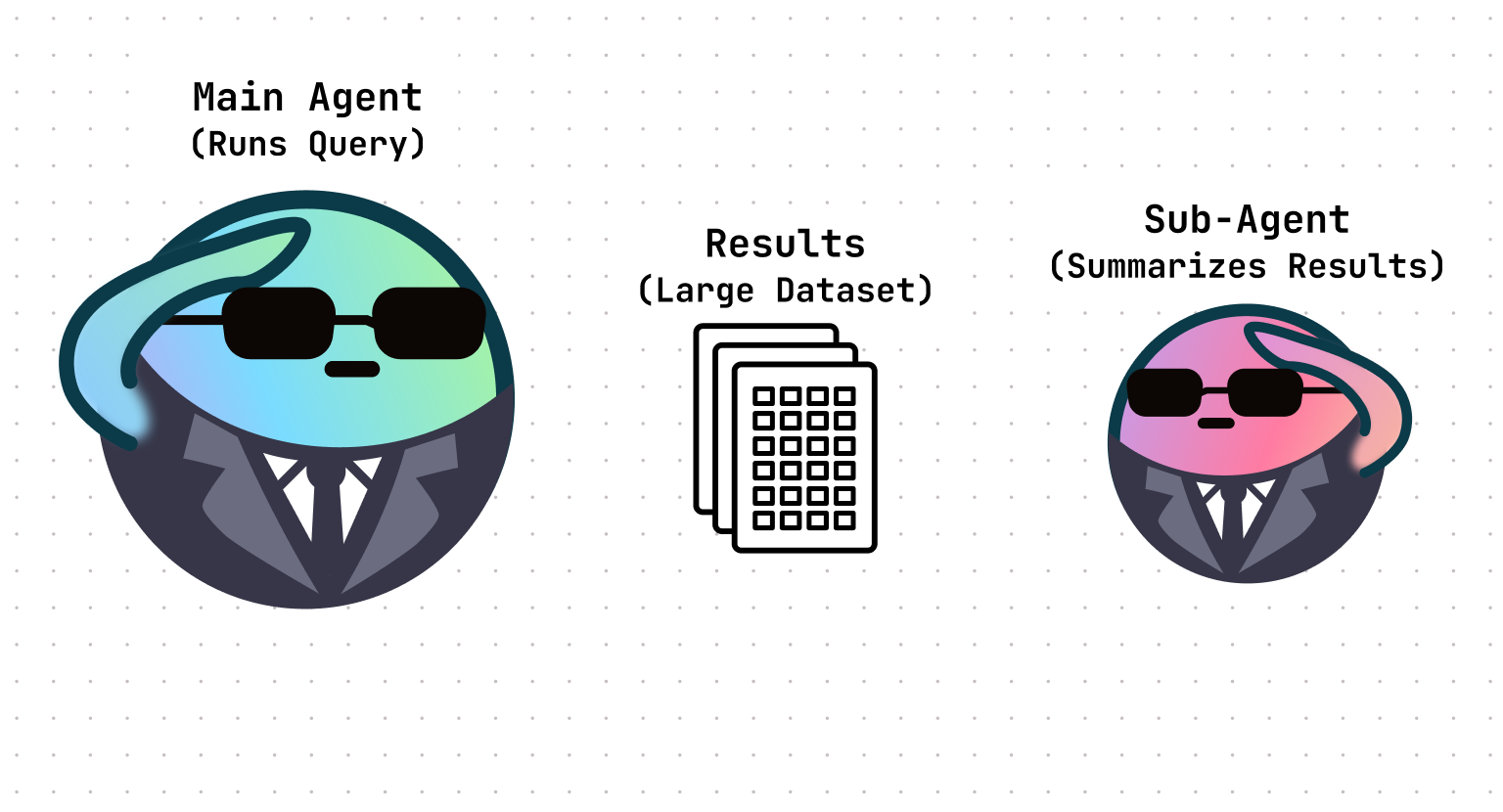
Summarization tool
After running a query, the agent hands results to a sub-agent for summarization. Since the sub-agent has its own context window, it can process large results without clogging up the context window of the main agent.
Why we built it: This helps queries run faster and brings context from each query into the comprehensive summary that the main agent provides at the end.
The real hard parts #
If we're really getting down to the nitty-gritty, here are some of the biggest engineering hurdles we had to work through along the way.
Conversation memory isn’t real, until you make it real
When trying to build an AI chatbot that can hold meaningful back-and-forth conversations, one of the challenges is that LLMs don’t actually remember anything. Every request starts as a blank slate with no hidden memory or internal state. As a result, if you want a model to “remember” what’s already happened in a conversation, you have to rebuild that memory yourself … every. single. time.
That means faithfully reconstructing the full story: who said what, which tools ran, what data came back, and what changed along the way. It’s like replaying the whole conversation from scratch on every turn, and doing it perfectly, or the model can start to lose the plot.
This is straightforward if your agent is just performing simple linear actions with small inputs and outputs, but Omni’s chats are more complex. The AI doesn’t run any queries itself — it generates SQL, passes it to the browser, waits for results, then gets those results back in Arrow format. These results have non-serializable types and need to be transformed into CSVs before they can be reintroduced to the conversation.
We also had to balance performance and cost. You can’t just dump entire result sets into the model context; it’s too expensive and breaks prompt caching, which we rely on to keep things fast and predictable. But you also can’t change how prior messages are represented, or the cache becomes invalid.
During the transition, we had to ensure that everything built around our old chat format either stayed backward compatible or was safely migrated. That meant augmenting our existing conversation representation and layering in a translator that rewrites it into exactly what the AI backend expects.
Why it matters: Real memory makes multi-step planning reliable and debuggable. Misreport history, and the model starts believing it can do things it can’t. (Ask us how we know 😅)
AI can be annoyingly forgiving, so tests & guardrails aren’t optional
LLMs are optimistic. Even when you leave out crucial context, they’ll still try to help. That’s not always helpful.
To balance this pesky optimism, we built strict validation around tool inputs and outputs, detectors for malformed state, and integration tests that check behavior across steps (“after summarizing, don’t re-query unless filters changed”).
Why it matters: This helps us focus on and deliver more “it’s trustworthy in production” moments instead of just optimizing for “looks cool in a demo” ones. As a developer, if you accidentally miss a crucial piece of context in your system prompt for the AI, AI will still try to help. It wants to be helpful, but it can also lead to results being totally off base.
Getting the foundations right
As a precursor to all of this work, we needed to make sure every underlying piece was rock solid. Each tool needs to do exactly what it says it does, return the right data, and respect every guardrail along the way. That’s why we’ve stayed maniacally focused on quality before we even decided to evolve our AI assistant, Blobby, to agentic.
One essential element of the foundation is security and permissions. Our AI respects all security protocols and user permissions already defined in Omni, so the agent can only ever run as the current user. Queries execute with that user’s permissions, period. No shortcuts or hidden AI superpowers.
Why it matters: Agentic functionality is only effective when every part of the foundation is rooted in quality and trustworthiness. That consistency is what lets us safely and carefully give our AI more control, and why customers are trusting our AI to drive their decision-making.
Closing #
We chose the hard path because it’s the only way to engineer a system that respects your permissions and definitions at every step. We rewired Omni not just to be smarter, but to be the system you can trust with enterprise decisions.
In a world where AI makes things easier but sometimes gets it wrong, we did it the hard way so your teams can ask harder questions, then trust the answers they get.
Want to see where it’s headed? Check out our weekly engineering development demos to see what we’re building next.