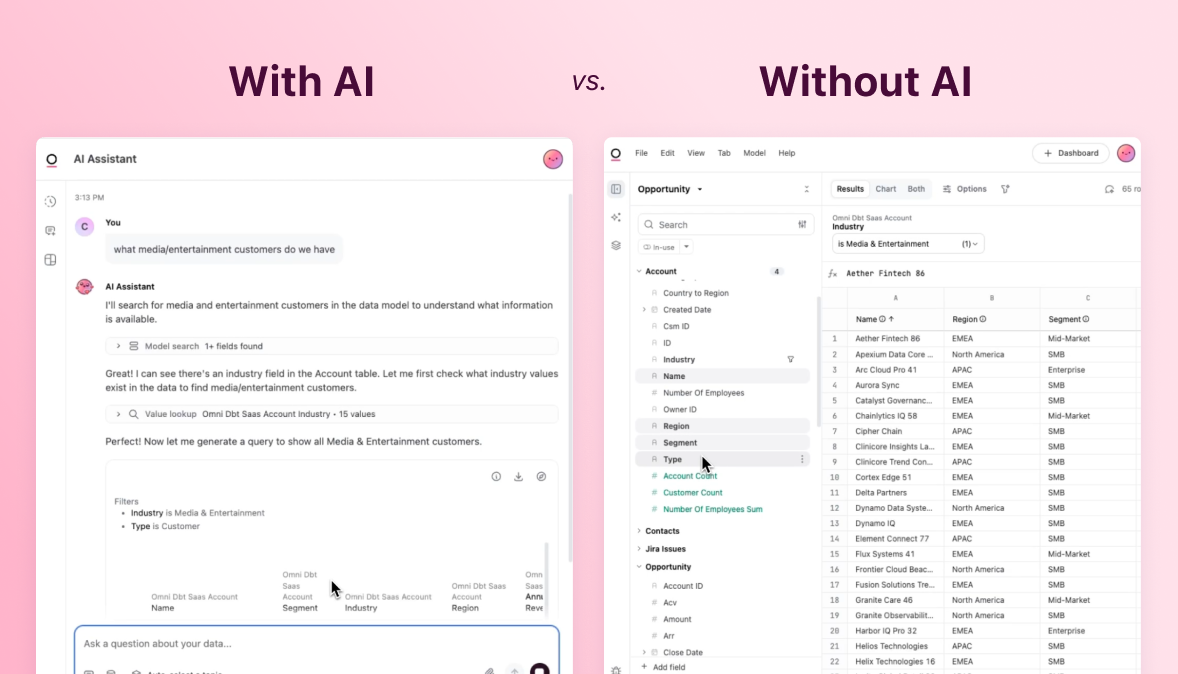
Text-to-SQL converts a natural language question into a SQL query against a database using a large language model. While it can work sometimes, the real danger is that text-to-SQL fails silently and confidently. The output may look right, even if it’s wrong.
The challenge isn’t generating SQL, it’s verifying the answer.
Verifying text-to-SQL output is especially difficult when you’re relying on it to serve non-technical users. If the number looks reasonable, a business user may just move on. Catching the error requires reading the generated SQL and understanding it, the same expertise the tool was supposed to replace.
In 2025, Google Cloud identified six distinct failure modes in text-to-SQL systems, three of which are fundamental. Typically, text-to-SQL failures occur for three structural reasons: domain-specific metrics the LLM cannot interpret, non-determinism (where the same question produces different SQL and different answers), and wrong joins on multi-table queries.
All three failure modes produce metric drift, a problem that occurs when queries return different numbers for the same metric, such as "revenue" or "churn." When you’re counting on data to make decisions, this simply doesn’t work. Another issue is permissions. When an LLM generates SQL against the schema, you don’t have an additional boundary in place to check permissions and enforce who should have access to run the query.

Better models don’t fix these failures, since it’s not an issue of AI capability. On traditional benchmarks like Spider 1.0, LLMs score over 86% execution accuracy. On enterprise-scale benchmarks, the numbers collapse. GPT-5 completes 29% of tasks in agentic mode on BIRD-Interact. The reason it’s so hard for LLMs to get it right on enterprise data is the lack of context and guardrails to help AI interpret and follow the guidelines of your business.
Today, most major AI analytics tools convert natural language to SQL. Some augment the process with retrieval, fine-tuning, or curated context graphs. While these additions improve benchmark scores, they don't address the structural root cause, and the LLM still generates new SQL against the schema every time rather than querying governed definitions. And because each query is generated from scratch, there’s nothing to verify it against. The only way to check the answer is to read the SQL and reason through it manually.
dbt Labs' latest benchmark confirms the pattern: even as LLMs improve at writing SQL, “failure looks like a plausible but incorrect answer”.
This is why a semantic layer is essential for providing reusable definitions, guardrails, and access controls to improve AI reliability on enterprise data in production. Instead of rewriting new SQL each time, a semantic layer creates a shared vocabulary to help AI interpret natural language questions, pull the right fields, and reason through the correct join paths — consistently. And row-level security travels with the user, so permissions are enforced whether the question comes from a dashboard or an AI-generated query.
In Omni, the additional AI context layer allows you to provide AI with further understanding of how your business speaks and how things should be used by capturing synonyms, sample values and queries, and more.

Let’s take a look at how text-to-SQL vs. semantic queries stack up for these common challenges 👇
Text-to-SQL misinterprets domain-specific metrics #
A business user asks "What is our average FRT by tier this quarter?" The LLM interprets FRT as "First Resolution Time" instead of "First Response Time." Or it picks a random timestamp column. The SQL runs and the numbers look fine. They measure the wrong thing.
This is not a rare edge case. An analysis of 4,602 incorrect SQL queries identified 29 error types across seven categories. Schema-level errors, including wrong column selection and semantic misinterpretation, account for 81.2% of failures. Syntax errors account for only 18.8%.
The problem is not that LLMs write bad SQL. The problem is that they write plausible SQL that means the wrong thing. And the person who asked the question often can’t tell the difference. The output is still SQL. Verifying it requires the same expertise the tool was supposed to replace.
In production, databases are full of domain-specific acronyms, custom metric definitions, and institutional knowledge baked into business processes. The LLM sees column names and table structures. It doesn’t see what the business means by "FRT" or "active subscriber" or "qualified pipeline."
The fix applied by a semantic model is defining what the business actually means when users ask for things that don’t match exactly what’s in your warehouse. Just as a business analyst has to learn all the metrics that matter to your business, so does an LLM.
In the example below, you can see the definition pulled for avg_frt, as well as the additional ai_context which captures all the ways users may actually ask about the question in natural language.
Text-to-SQL returns different answers to the same question #
Ask a revenue question today, get one answer. Ask tomorrow, get another. It’s probably not a game your finance team wants you to play.
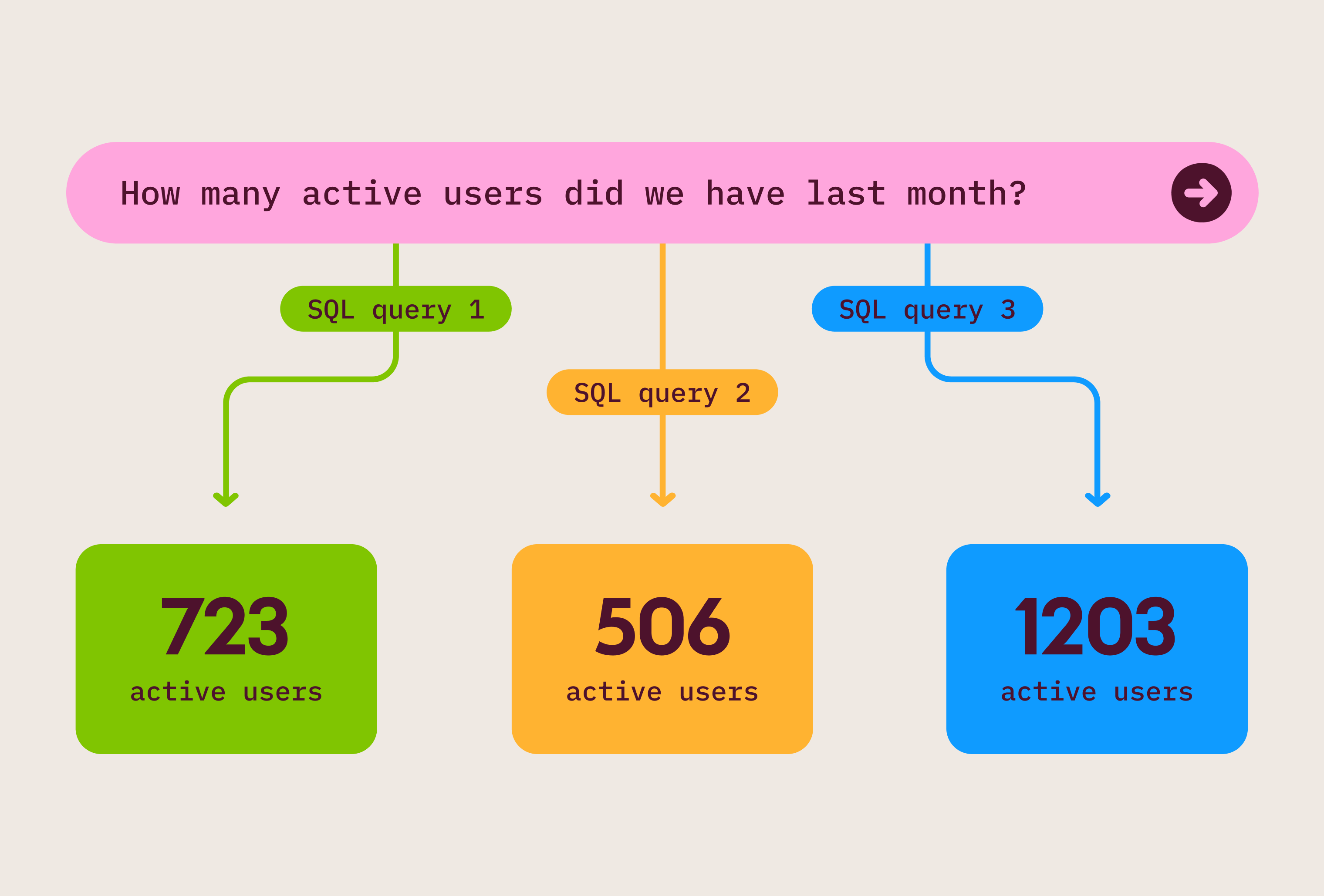
This is non-determinism, and it occurs when the same question can produce different SQL on different runs. Different SQL means different numbers.
That’s how metric drift starts. Each ad-hoc query is a fork. The metric shifts between runs, and trust in the numbers erodes because no one catches it in real time. The business user sees a number. They don’t see the SQL that produced it. The drift is invisible. Until it isn’t.
At launch, Salesforce's production text-to-SQL agent achieved only a ~50% efficacy score. To reach ~80%, they generated 10 candidate SQL queries per prompt and scored them for consistency. This workaround has limits. Majority voting over SQL candidates is flawed, and the gap widens with more samples.
Schema evolution compounds the problem. When tables are added, split, or merged, execution accuracy drops by up to 24 points. The same questions produce different results on the evolved schema.
The semantic model provides the guardrails needed for determinism. In Omni, the same question routes to the same Topic (curated dataset), runs the same query, and delivers the same answer. The consistency is architectural because metric definitions, join paths, and aggregation logic are fixed in the model.
When the same revenue question runs through Omni's semantic layer, Omni’s AI agent generates a governed query.
This query produces the same dialect SQL every time. Three different LLM-generated SQL variants would produce three different numbers. AI running on a semantic layer produces one.
Text-to-SQL wanders off join paths #
A business user asks for MRR (monthly recurring revenue) by product line. The LLM joins orders directly to products, skipping the subscription model. The result returned is total order value, not recurring revenue. The SQL runs without errors and the number looks reasonable. It’s wrong. A finance analyst might catch the missing subscription join, but the business user who asked the question would not. They see a revenue number and move on.
This failure is common on complex schemas. On LiveSQLBench-Large, popular LLMs achieve between 30-36% accuracy. These schemas have roughly 1,000 columns and 54 tables. Even the top performer on Spider 2.0-Lite reaches only 69.65%. That means nearly one in three queries fail on a curated benchmark, before production complexity is added.
Agentic approaches with multi-turn correction don’t solve this. On BIRD-Interact, GPT-5 completed 29% of tasks in agentic mode and 14.5% in conversational mode.
When asking this same question on top of a semantic layer, the join paths are already pre-defined in the model. The MRR measure references the correct path by definition, and AI follows the guidelines any time MRR is referenced.
Comparing text-to-SQL vs. semantic layer #
Here’s how text-to-SQL vs. AI on a semantic layer approach tasks differently.
Dimension | Text-to-SQL: LLM writes raw SQL | Semantic layer: LLM queries governed metrics |
|---|---|---|
Join logic | LLM infers from schema | Pre-defined in model |
Metric definitions | LLM interprets from column names | Governed, versioned definitions |
Determinism | Same question can return different SQL | Same metric resolves the same way every time |
Verifiability | User gets raw SQL. Only someone who reads SQL can check if the answer is right. | User sees named metrics, governed definitions, and filters in a workbook. SQL is available to dig deeper if needed. |
Security | LLM generates arbitrary SQL. 0.44% poisoned training data → 79% injection success. | Queries constrained to semantic model. Row-level security enforced. |
The pattern is consistent — every failure mode traces to the same root cause when the LLM operates against raw schema instead of governed definitions. This holds whether the LLM queries the schema directly or receives augmented context through retrieval or fine-tuning. The failure is in what the LLM queries, not how it queries.
We’ve built the semantic layer for AI analytics that helps you mitigate these issues. We’d love to show you.