Don’t worry. It’s 2026. This will end up being a blog about AI. Bear with me.
When you’re first building a startup, you sometimes have bad ideas. When we started Omni in 2022, one of our early hypotheses was that SQL and point-and-click querying should not be separate worlds. A better BI tool should let people move between them.
In that sort of manic blank-canvas mode in those first couple of weeks of building, I had what I thought was an epic idea. We were building the core semantic query on Calcite. Calcite can generate SQL, but it can also parse SQL. What if we built a two-way binding? A user could use the point-and-click UI to select fields and build SQL, or write SQL directly, and have Omni parse it into a semantic query that they could keep editing in the UI.
To make this work, we needed a “query model”: a temporary layer on top of the core semantic model. The parser could pull out arbitrary views and fields on-the-fly, put them into this query model, and thereby replicate SQL by layering the query model on top of the main model. We also needed “OmniSQL”: a flavor of SQL that used ${} to reference model objects and OMNI_* prefixed functions to extend SQL with semantic concepts. After a few weeks of hacking on the parse side along with the generation code, I had a working proof of concept. I thought it was super cool.
No one else on the team was so sure.
Nevertheless, over the next six months, I kept pushing. I wrote hundreds of parser-specific tests. For our query generation tests, I wrote in an automatic round-trip check that used the parser to parse our generated SQL back into a semantic query and assert that it matched the original test query. As I encountered round pegs of SQL that didn’t quite fit into square holes of semantic querying, I kept forcibly re-shaping the holes.
The feature earned itself a name: “magic sauce mode.” The code got kinda complicated. Sometimes it worked, and sometimes people who saw it working said “neat.” More often it didn’t. And no potential first customer ever said “oh for sure I’ll buy because you have this novel SQL-to-query two-way binding”.
Interestingly, even though magic sauce wasn't going anywhere, some of the core components we built for it did. The model layering mechanism, the structure that OmniSQL forced on our query generation, and a well-tested snippet parser for field definitions all became important pieces of Omni. Those pieces, not magic sauce itself, became part of our core differentiator as we first went to market.

Magic sauce didn’t work well because:
Cross-dialect SQL parsing. It was not fully supported out of the box in Calcite, and users expected to write SQL in their database dialect, not Calcite’s native SQL flavor.
No one wanted to learn Omni functions. Queries showed up best in the UI when users used our
OMNI_*custom SQL functions, but no one wanted to learn them.Hard to read parser errors. Calcite’s errors weren’t what expert SQL users were used to reading when they messed up syntax, and SQL errors are inscrutable enough as it is.
Dense code took a lot of effort to understand. It became harder to justify sinking my time (and the time of other engineers working on “semantics,” as the team grew) into this feature code. The code was well tested, decently documented, and modular, but it really was dense.
By early 2023, “magic sauce” mode had been renamed to the much less exciting “Advanced SQL” mode, tucked into a corner of the UI, and mostly abandoned. For a while longer we kept adding new query generation features into the round-trip test functionality, which involved updating the parser to understand each new query behavior, but eventually we just started skipping that too for new features. No one was using “Advanced SQL”, so it didn’t make sense to keep paying this tax on new work.
So it turned out magic sauce mode was a bad idea. I told myself, and anyone who cared to ask about it, that if nothing else, the framework had forced useful structure into Omni’s semantic layer. Maybe someday someone would go do the chore to rip the full query parsing code out. That was the narrative towards the end of 2023, and then I (and certainly everyone else) mostly stopped thinking about this feature at all.
So fast forward to early 2026. Omni had 200 employees, rather than 20. We had hundreds of customers, rather than a handful. More importantly for this story, “Blobby”, our AI mascot (now branded “Omni Agent” by the same corporate process that turned "magic sauce" into "Advanced SQL") had been generating queries using an LLM for almost two years: first, as a quick, mostly unstaffed proof of concept, then as a top-level feature, and by 2026 as the most important part of the product going forward.
Even a year ago, Blobby was quite good at generating queries in the semantic model! It initially worked by showing the LLM the definition of a topic and giving it the schema of our semantic query object as a tool (choose field names, sorts, filters, etc). But that requirement to pick a topic and only generate queries using fields in the model quickly proved too restrictive to answer the open-ended questions users were asking. We gave Blobby more query generation capabilities: switching topics, creating custom fields, filtering by another query, joining results from multiple queries, and even using a query it had generated as a fact table for another query.
So, by February 2026 Blobby was even better. The uncomfortable question was whether that was good enough. In 2025, our response to the question of “why not just text-to-SQL?” had been threefold:
Hallucination. Without the constraint of a semantic model, the LLM can just straight-up do the wrong thing
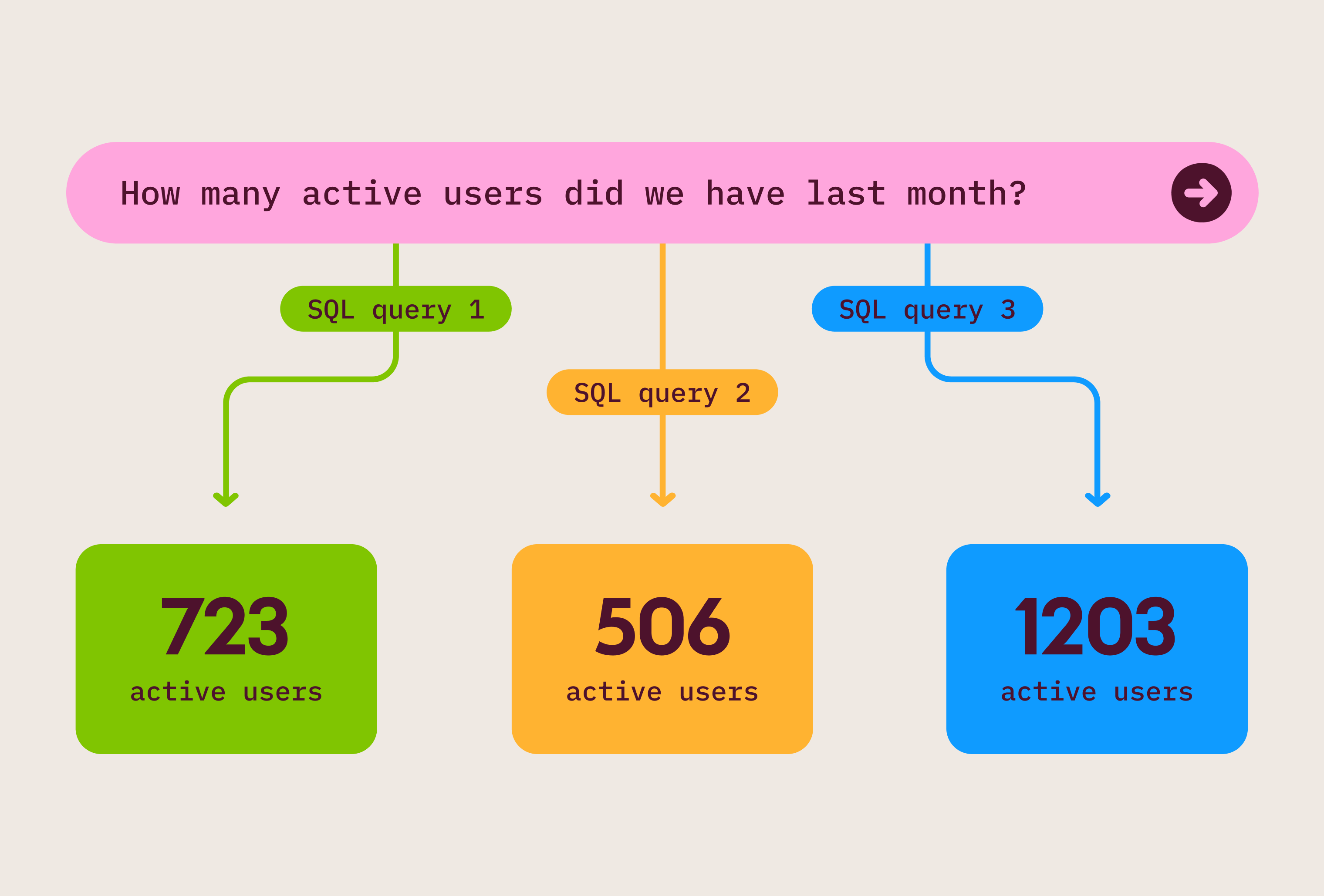
Verification. So the LLM spits out a SQL query to answer your question. Even if it didn’t make an error, how can you tell you asked the right question? The query UI allows you to actually see what it did without being a SQL expert.
Context management. You need a semantic model to define key concepts in a structured way so you only show the LLM what it needs to see.
The problem with this tripod was, in 2026, argument one, hallucination, was losing steam. LLMs have gotten really, really good. And by forcing the LLM to generate a semantic query we were limiting its expressivity in a way that was starting to show when baked off against competitors that allowed for arbitrary SQL.
The last week of February was bad. Not existentially bad, but startup-bad: too many fires, too little sleep, and several meetings where we asked, with more seriousness than usual, whether our whole approach to Blobby was turning out to be wrong.
Friday that week, with things a little calmer, a plan for Blobby in place (switch from Haiku 4.5 to Sonnet 4.6, of course), I had what was probably a bad idea.
What if the LLM could generate SQL, but stay within the semantic model? What if there was a hidden, well-tested feature sitting in our codebase waiting for someone to just use it for something like that?
That day, I had Claude Code glue up the APIs and spec out the tool description for Blobby to use our full query parsing code. It worked! And then the second thing I tried seemed to hit a show-stopping bug where the parsing mangled the query and dropped a join. Bad idea. The upgrade to Sonnet 4.6 would have to be sufficient. I walked away from my “blobby-sql” branch. Before I did, I told our CTO Chris about the bad idea: hook Blobby up to the old magic sauce code, ha.
Two weeks later, everything a bit calmer, Chris pinged me. What if we actually did it? Could it actually work? I went back to the code. The bug I thought I had seen hadn’t been a bug, just the symptom of me being tired at the end of a long week. The original reasons magic sauce didn’t work suddenly looked different.

There was still a lot to do. The query parsing code didn’t even know about topics in Omni! And the core query generation features we had punted on round-tripping via the parser since 2023 needed to be implemented. But building on a well-thought-out base, with good tests, using Claude Code, it was possible to move very fast.
We started using “Blobby SQL” internally, and the feedback was clear: Blobby was more powerful with this new capability. It had no problem understanding the semantic model concepts, using the correct ${} syntax to reference fields, views, and topics, writing our OMNI_FX* functions to generate Excel-style calculations, OMNI_PIVOT to pivot the query, and so on.
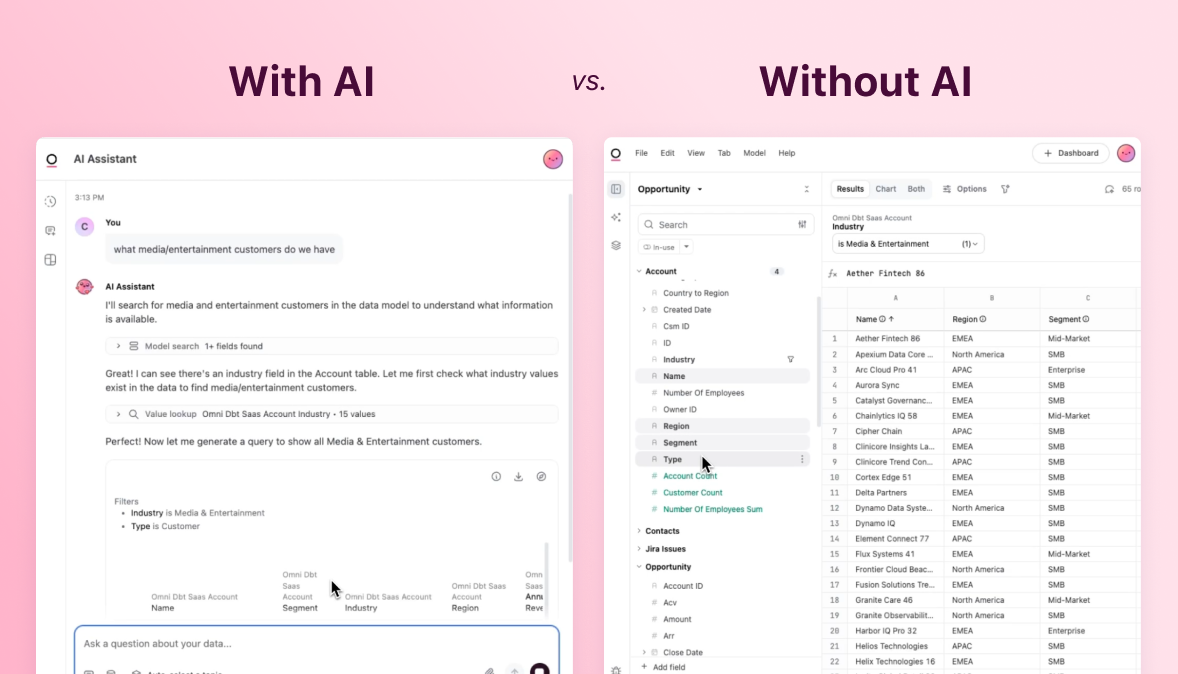
Text-to-SQL gives you an answer. Parsed OmniSQL gives you an answer you can inspect, edit, and tie back to the semantic model.
This is where the compiler-y bit actually mattered. Raw text-to-SQL gives you a string. Maybe it runs. Maybe it is right. But after generation, the product mostly has a blob of text.
OmniSQL is different. It is basically a DSL over the semantic model, and the parser is the compiler front-end. When Blobby wrote ${subscriptions.net_revenue_retention} or OMNI_PIVOT(...), it was not just producing characters that happened to be valid SQL-ish syntax. It was naming Omni concepts in a language we could parse back into the same query model that powered the UI.
In this new approach, AI had all the expressive power of SQL, while retaining the verification and context management provided by the semantic model.
So we shipped it to everyone. Now it powers one of the core features we're betting on: a bet I think we’ll win.
So was “magic sauce” mode a bad idea after all? I mean, yes. We probably shouldn’t have done it, and, given that we did, I probably should have deleted the code three years ago. Sometimes it’s better to be lucky than smart. Or maybe it’s better to move fast and try as many things as possible. That's what we do here at Omni, though it doesn't usually take four years for an idea to work out.